PCI DSS 4.0 Requirements

The new requirements cover everything from protecting cardholder data to implementing user access controls, zero trust security measures, and frequent penetration (pen) testing. Each major requirement defined in the updated PCI DSS 4.0 is summarized below, with tables breaking down the specific compliance stipulations and providing tips or best practices for meeting them.
Citation: The PCI DSS v4.0
PCI DSS 4.0 requirements and best practices
Every PCI DSS 4.0 requirement starts with a stipulation that the processes and mechanisms for implementation are clearly defined and understood. The best practice involves updating policy and process documents as soon as possible after changes occur, such as when business goals or technologies evolve, and communicating changes across all relevant business units.
Jump to the other requirements below:
- Build and maintain a secure network and systems
- Protect Account Data
- Maintain a Vulnerability Management Program
- Implement Strong Access Control Measures
- Regularly Monitor and Test Networks
- Maintain an Information Security Policy
Build and maintain a secure network and systems
Requirement 1: Install and maintain network security controls
Network security controls include firewalls and other security solutions that inspect and control network traffic. PCI DSS 4.0 requires organizations to install and properly configure network security controls to protect payment card data.
Requirement 2: Apply secure configurations to all system components
Attackers often compromise systems using known default passwords or old, forgotten services. PCI DSS 4.0 requires organizations to properly configure system security settings and reduce the attack surface by turning off unnecessary software, services, and accounts.
Protect account data
Requirement 3: Protect stored account data
Any payment account data an organization stores must be protected by methods such as encryption and hashing. Organizations should also limit account data storage unless it’s necessary and, when possible, truncate cardholder data.
Requirement 4: Protect cardholder data with strong cryptography during transmission over open, public networks
While requirement 3 applies to stored card data, requirement 4 outlines stipulations for protecting cardholder data in transit.
Maintain a vulnerability management program
Requirement 5: Protect all systems and networks from malicious software
Organizations must take steps to prevent malicious software (a.k.a., malware) from infecting the network and potentially exposing cardholder data.
Requirement 6: Develop and maintain secure systems and software
Development teams should follow PCI-compliant processes when writing and validating code. Additionally, install all appropriate security patches immediately to prevent malicious actors from exploiting known vulnerabilities in systems and software.
Implement strong access control measures
Requirement 7: Restrict access to system components and cardholder data by business need-to-know
This PCI DSS 4.0 requirement aims to limit who and what has access to sensitive cardholder data and CDEs to prevent malicious actors from gaining access through a compromised, over-provisioned account. “Need to know” means that only accounts with a specific need should have access to sensitive resources; it’s often applied using the “least-privilege” approach, which means only granting accounts the specific privileges needed to perform a job role.
Requirement 8: Identify users and authenticate access to system components
Organizations must establish and prove the identity of any users attempting to access CDEs or sensitive data. This requirement is core to the zero trust security methodology which is designed to limit the scope of data access and theft once an attacker has already compromised an account or system.
Requirement 9: Restrict physical access to cardholder data
Malicious actors could gain access to cardholder data by physically interacting with payment devices or tampering with the hardware infrastructure that stores and processes that data. These PCI DSS 4.0 requirements outline how to prevent physical data access.
Regularly monitor and test networks
Requirement 10: Log and monitor all access to system components and cardholder data
User activity logging and monitoring will help prevent, detect, and mitigate CDE breaches. PCI DSS 4.0 requires organizations to collect, protect, and review audit logs of all user activities in the CDE.
Requirement 11: Test security of systems and network regularly
Researchers and attackers continuously discover new vulnerabilities in systems and software, so organizations must frequently test network components, applications, and processes to ensure that in-place security controls are still adequate. ge changes; ensure alerts are monitored.
Maintain an information security policy
Requirement 12: Support information security with organizational policies and programs
The final requirement is to implement information security policies and programs to support the processes described above and get everyone on the same page about their responsibilities regarding cardholder data privacy.
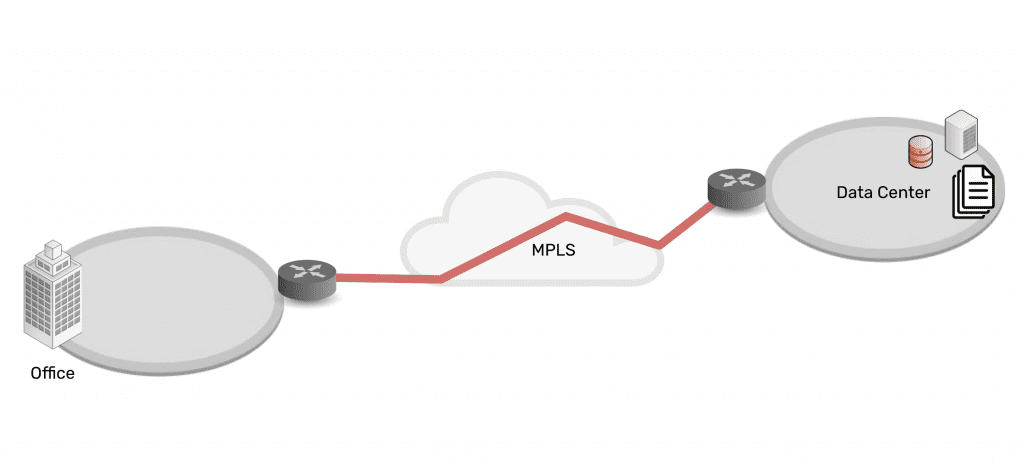
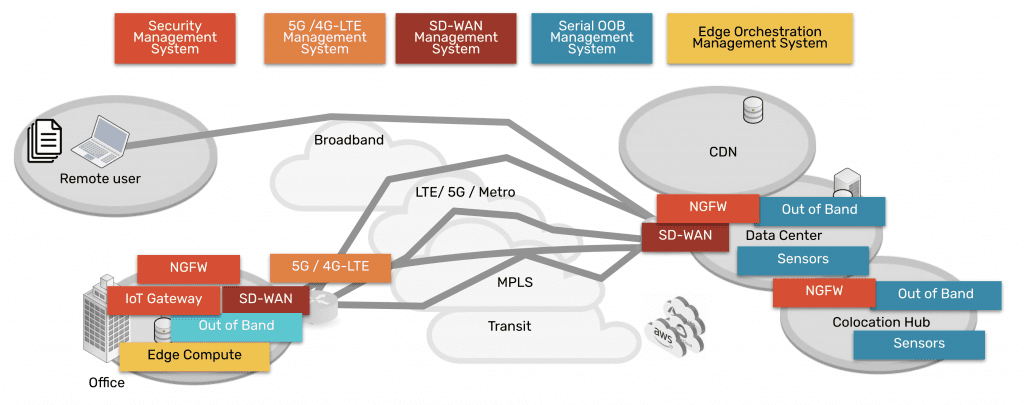
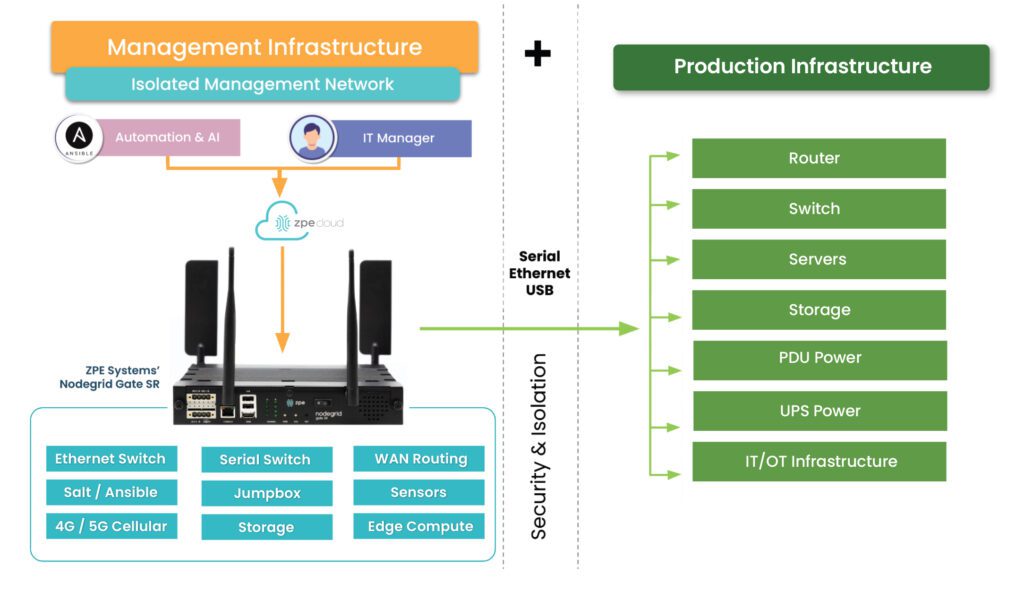
Isolate your CDE and management infrastructure with Nodegrid
The Nodegrid out-of-band (OOB) management platform from ZPE Systems isolates your control plane and provides a safe environment for cardholder data, management infrastructure, and ransomware recovery. Our vendor-neutral, Gen 3 OOB solution allows you to host third-party tools for automation, security, troubleshooting, and more for ultimate efficiency.
Ready to know more about PCI DSS 4.0 Requirements?
Learn how to meet PCI DSS 4.0 requirements for network segmentation and security by downloading our isolated management infrastructure (IMI) solution guide.
Download the Guide







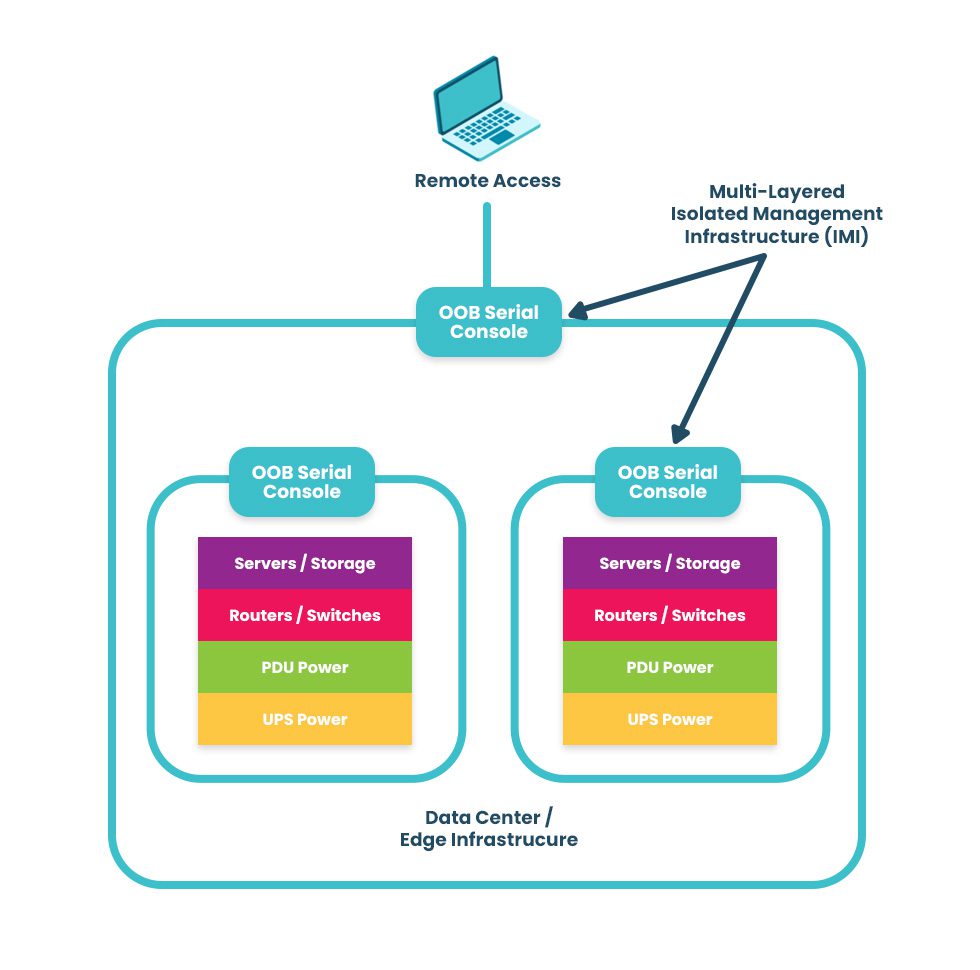 An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between
An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between