Why Gen 3 Out-of-Band Is Your Strategic Weapon in 2025

I think it’s time to revisit the old school way of thinking about managing and securing IT infrastructure. The legacy use case for OOB is outdated. For the past decade, most IT teams have viewed out-of-band (OOB) as a last resort; an insurance policy for when something goes wrong. That mindset made sense when OOB technology was focused on connecting you to a switch or router.
Technology and the role of IT have changed so much in the last few years. There’s a lot more pressure on IT folks these days! But we get it, and that’s why ZPE’s OOB platform has changed to help you.
At a minimum, you have to ensure system endpoints are hardened against attacks, patch and update regularly, back up and restore critical systems, and be prepared to isolate compromised networks. In other words, you have to make sure those complicated hybrid environments don’t go off the rails and cost your company money. OOB for the “just-in-case” scenario doesn’t cut it anymore, and treating it that way is a huge missed opportunity.
Don’t Be Reactive. Be Resilient By Design.
Some OOB vendors claim they have the solution to get you through installation day, doomsday, and everyday ops. But if I’m candid, ZPE is the only vendor who can live up to this standard. We do what no one else can do! Our work with the world’s largest, most well-known hyperscale and tech companies proves our architecture and design principles.
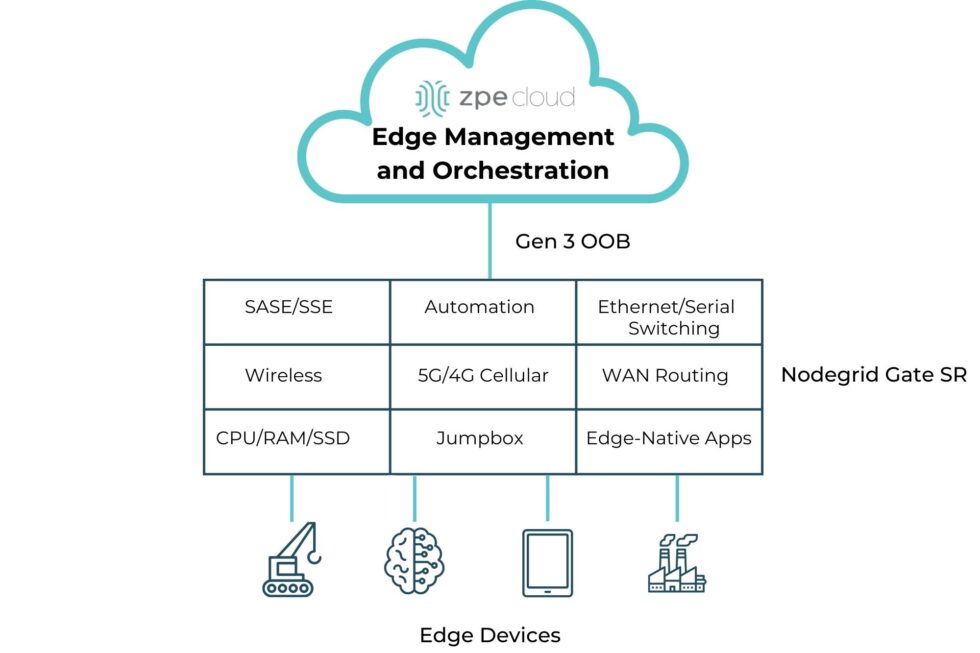
This Gen 3 out-of-band (aka Isolated Management Infrastructure) is about staying in control no matter what gets thrown at you.
OOB Has A New Job Description
Out-of-band is evolving because of today’s radically different network demands:
- Edge computing is pushing infrastructure into hard-to-reach (sometimes hostile) environments.
- Remote and hybrid ops teams need 24/7 secure access without relying on fragile VPNs.
- Ransomware and insider threats are rising, requiring an isolated recovery path that can’t be hijacked by attackers.
- Patching delays leave systems vulnerable for weeks or months, and faulty updates can cause crashes that are difficult to recover from.
- Automation and Infrastructure as Code (IaC) are no longer nice-to-haves – they’re essential for things like initial provisioning, config management, and everyday ops.
It’s a lot to add to the old “break/fix” job description. That’s why traditional OOB solutions fall short and we succeed. ZPE is designed to help teams enforce security policies, manage infrastructure proactively, drive automation, and do all the things that keep the bad stuff from happening in the first place. ZPE’s founders knew this evolution was coming, and that’s why they built Gen 3 out-of-band.
Gen 3 Out-of-Band Is Your Strategic Weapon
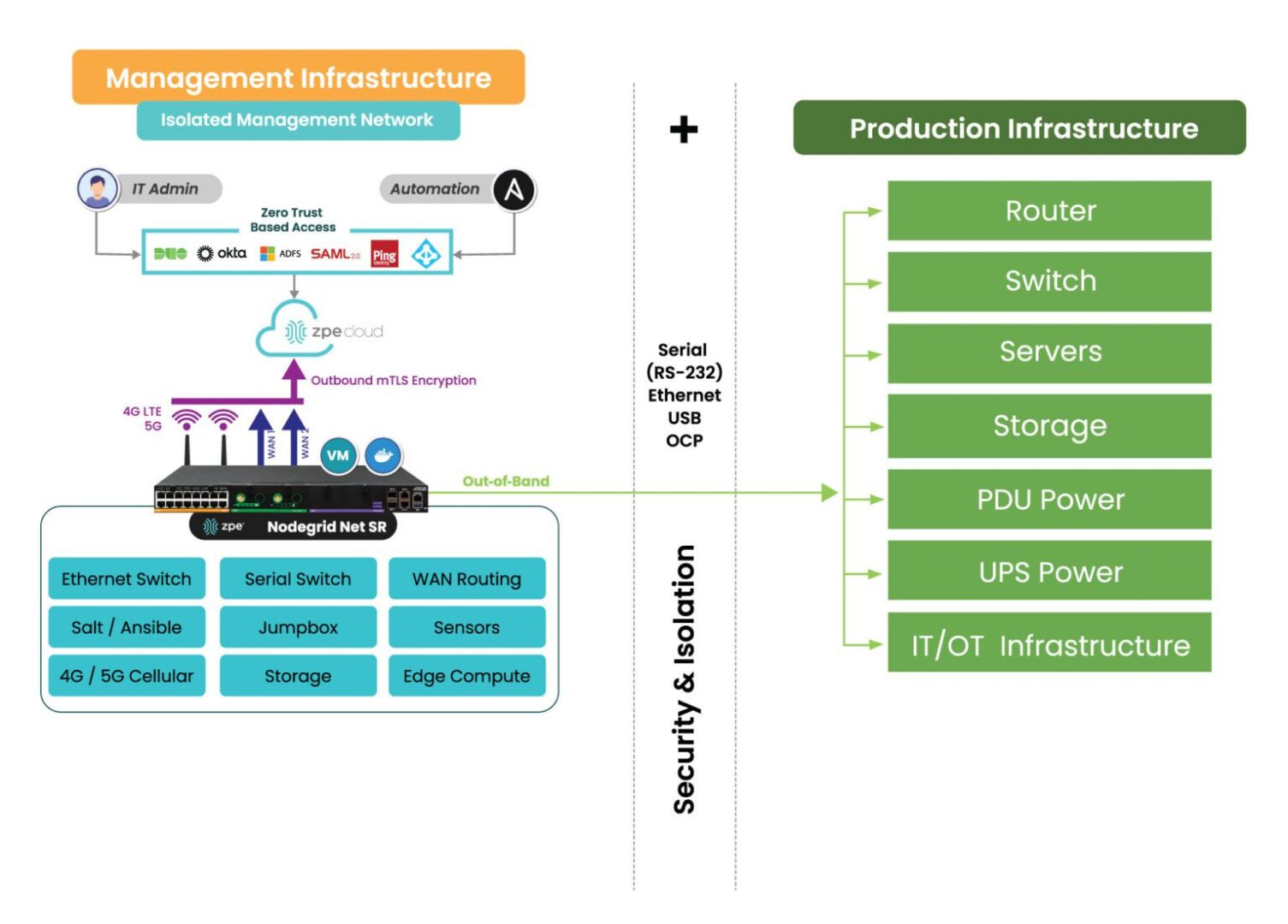
Unlike normal OOB setups that are bolted onto the production network, Gen 3 out-of-band is physically and logically separated via Isolated Management Infrastructure (IMI) approach. That separation is key – it gives teams persistent, secure access to infrastructure without touching the production network.
This means you stay in control no matter what.

Image: Gen 3 out-of-band management takes advantage of an approach called Isolated Management Infrastructure, a fully separate network that guarantees admin access when the main network is down.
Imagine your OOB system helping you:
- Push golden configurations across 100 remote sites without relying on a VPN.
- Automatically detect config drift and restore known-good states.
- Trigger remediation workflows when a security policy is violated.
- Run automation playbooks at remote locations using integrated tools like Ansible, Terraform, or GitOps pipelines.
- Maintain operations when production links are compromised or hijacked.
- Deploy the Gartner-recommended Secure Isolated Recovery Environment to stop an active cyberattack in hours (not weeks).
Gen 3 out-of-band is the dedicated management plane that enables all these things, which is a huge strategic advantage. Here are some real-world examples:
- Vapor IO shrunk edge data center deployment times to one hour and achieved full lights-out operations. No more late-night wakeup calls or expensive on-site visits.
- IAA refreshed their nationwide infrastructure while keeping 100% uptime and saving $17,500 per month in management costs.
- Living Spaces quadrupled business while saving $300,000 per year. They actually shrunk their workload and didn’t need to add any headcount.
OOB is no longer just for the worst day. Gen 3 out-of-band gives you the architecture and platform to build resilience into your business strategy and minimize what the worst day could be.