IT Infrastructure Management Best Practices

A single hour of downtime costs organizations more than $300,000 in lost business, making network and service reliability critical to revenue. The biggest challenge facing IT infrastructure teams is ensuring network resilience, which is the ability to continue operating and delivering services during equipment failures, ransomware attacks, and other emergencies. This guide discusses IT infrastructure management best practices for creating and maintaining more resilient enterprise networks.
.
IT infrastructure management best practices
The following IT infrastructure management best practices help improve network resilience while streamlining operations. Click the links on the left for a more detailed look at the technologies and processes involved with each.
Isolated management infrastructure (IMI)
Management interfaces provide the crucial path to monitoring and controlling critical infrastructure, like servers and switches, as well as crown-jewel digital assets like intellectual property (IP). If management interfaces are exposed to the internet or rely on the production network, attackers can easily hijack your critical infrastructure, access valuable resources, and take down the entire network. This is why CISA released a binding directive that instructs organizations to move management interfaces to a separate network, a practice known as isolated management infrastructure (IMI).
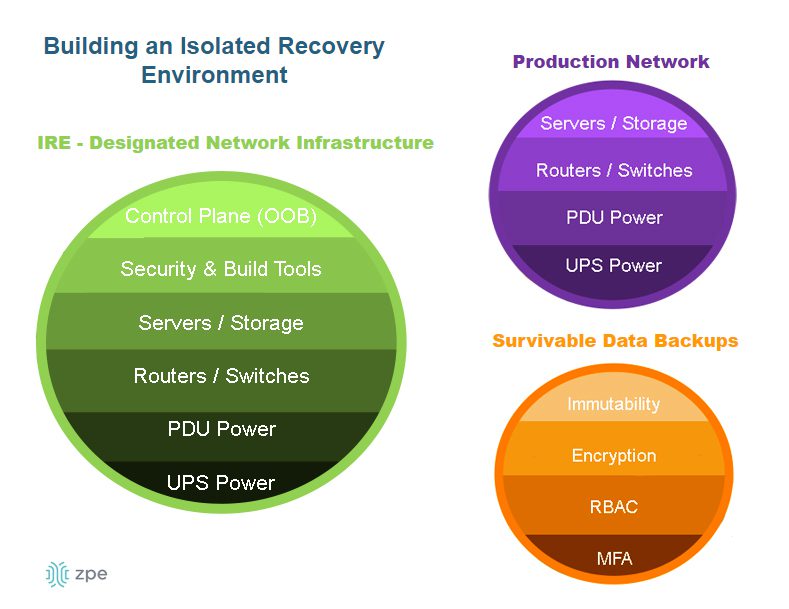
The best practice for building an IMI is to use Gen 3 out-of-band (OOB) serial consoles, which unify the management of all connected devices and ensure continuous remote access via alternative network interfaces (such as 4G/5G cellular). OOB management gives IT teams a lifeline to troubleshoot and recover remote infrastructure during equipment failures and outages on the production network. The key is to ensure that OOB serial consoles are fully isolated from production and can run the applications, tools, and services needed to fight through a ransomware attack or outage without taking critical infrastructure offline for extended periods. This essentially allows you to instantly create a virtual War Room for coordinated recovery efforts to get you back online in a matter of hours instead of days or weeks. 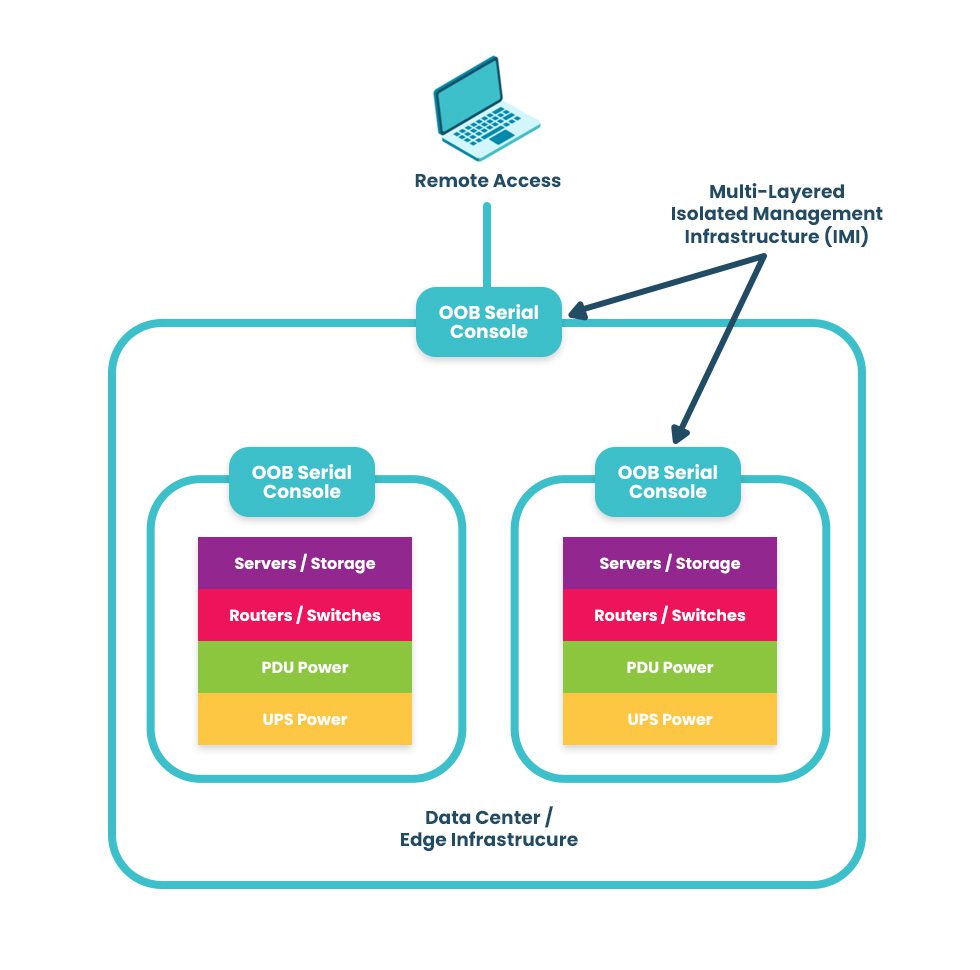 An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between 1 and 6 months to fully recover from an attack, with costs and revenue losses mounting with every day of downtime. The best practice is to use OOB serial consoles to create an isolated recovery environment (IRE) where teams can restore and rebuild without risking reinfection.
An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between 1 and 6 months to fully recover from an attack, with costs and revenue losses mounting with every day of downtime. The best practice is to use OOB serial consoles to create an isolated recovery environment (IRE) where teams can restore and rebuild without risking reinfection.
.
Network and infrastructure automation
As enterprise network architectures grow more complex to support technologies like microservices applications, edge computing, and artificial intelligence, teams find it increasingly difficult to manually monitor and manage all the moving parts. Complexity increases the risk of configuration mistakes, which cause up to 35% of cybersecurity incidents. Network and infrastructure automation handles many tedious, repetitive tasks prone to human error, improving resilience and giving admins more time to focus on revenue-generating projects.
Additionally, automated device provisioning tools like zero-touch provisioning (ZTP) and configuration management tools like RedHat Ansible make it easier for teams to recover critical infrastructure after a failure or attack. Network and infrastructure automation help organizations reduce the duration of outages and allow small IT infrastructure teams to manage large enterprise networks effectively, improving resilience and reducing costs.
Vendor-neutral platforms
Most enterprise networks bring together devices and solutions from many providers, and they often don’t interoperate easily. This box-based approach creates vendor lock-in and technical debt by preventing admins from using the tools or scripting languages they’re familiar with, and it makes a fragmented, complex architecture of management solutions that are difficult to operate efficiently. Organizations also end up compromising on features, ending up with a lot of stuff they don’t need and too little of what they do need.
A vendor-neutral IT infrastructure management platform allows teams to unify all their workflows and solutions. It integrates your administrators’ favorite tools to reduce technical debt and provides a centralized place to deploy, orchestrate, and monitor the entire network. It also extends technologies like OOB, automation, and AIOps to otherwise unsupported legacy and mixed-vendor solutions. Such a platform is revolutionary in the same way smartphones were – instead of needing a separate calculator, watch, pager, phone, etc., everything was combined in a single device. A vendor-neutral management platform allows you to run all the apps, services, and tools you need without buying a bunch of extra hardware. It’s a crucial IT infrastructure management best practice for resilience because it consolidates and unifies network architectures to reduce complexity and prevent human error.
AIOps
AIOps applies artificial intelligence technologies to IT operations to maximize resilience and efficiency. Some AIOps use cases include:
- Security detection: AIOps security monitoring solutions are better at catching novel attacks (those using methods never encountered or documented before) than traditional, signature-based detection methods that rely on a database of known attack vectors.
- Data analysis: AIOps can analyze all the gigabytes of logs generated by network infrastructure and provide health visualizations and recommendations for preventing potential issues or optimizing performance.
- Root-cause analysis (RCA): Ingesting infrastructure logs allows AIOps to identify problems on the network, perform root-cause analysis to determine the source of the issues, and create & prioritize service incidents to accelerate remediation.
AIOps is often thought of as “intelligent automation” because, while most automation follows a predetermined script or playbook of actions, AIOps can make decisions on-the-fly in response to analyzed data. AIOps and automation work together to reduce management complexity and improve network resilience.
IT infrastructure management best practices for maximum resilience
Network resilience is one of the top IT infrastructure management challenges facing modern enterprises. These IT infrastructure management best practices ensure resilience by isolating management infrastructure from attackers, reducing the risk of human error during configurations and other tedious workflows, breaking vendor lock-in to decrease network complexity, and applying artificial intelligence to the defense and maintenance of critical infrastructure.
Need help getting started with these practices and technologies? ZPE Systems can help simplify IT infrastructure management with the vendor-neutral Nodegrid platform. Nodegrid’s OOB serial consoles and integrated branch routers allow you to build an isolated management infrastructure that supports your choice of third-party solutions for automation, AIOps, and more.
Want to learn how to make IT infrastructure management easier with Nodegrid?
To learn more about implementing IT infrastructure management best practices for resilience with Nodegrid, download our Network Automation Blueprint.

")