Edge Computing Use Cases in Banking

The banking and financial services industry deals with enormous, highly sensitive datasets collected from remote sites like branches, ATMs, and mobile applications. Efficiently leveraging this data while avoiding regulatory, security, and reliability issues is extremely challenging when the hardware and software resources used to analyze that data reside in the cloud or a centralized data center.
Edge computing decentralizes computing resources and distributes them at the network’s “edges,” where most banking operations take place. Running applications and leveraging data at the edge enables real-time analysis and insights, mitigates many security and compliance concerns, and ensures that systems remain operational even if Internet access is disrupted. This blog describes four edge computing use cases in banking, lists the benefits of edge computing for the financial services industry, and provides advice for ensuring the resilience, scalability, and efficiency of edge computing deployments.
4 Edge computing use cases in banking
1. AI-powered video surveillance
PCI DSS requires banks to monitor key locations with video surveillance, review and correlate surveillance data on a regular basis, and retain videos for at least 90 days. Constantly monitoring video surveillance feeds from bank branches and ATMs with maximum vigilance is nearly impossible for humans, but machines excel at it. Financial institutions are beginning to adopt artificial intelligence solutions that can analyze video feeds and detect suspicious activity with far greater vigilance and accuracy than human security personnel.
When these AI-powered surveillance solutions are deployed at the edge, they can analyze video feeds in real time, potentially catching a crime as it occurs. Edge computing also keeps surveillance data on-site, reducing bandwidth costs and network latency while mitigating the security and compliance risks involved with storing videos in the cloud.
2. Branch customer insights
Banks collect a lot of customer data from branches, web and mobile apps, and self-service ATMs. Feeding this data into AI/ML-powered data analytics software can provide insights into how to improve the customer experience and generate more revenue. By running analytics at the edge rather than from the cloud or centralized data center, banks can get these insights in real-time, allowing them to improve customer interactions while they’re happening.
For example, edge-AI/ML software can help banks provide fast, personalized investment advice on the spot by analyzing a customer’s financial history, risk preferences, and retirement goals and recommending the best options. It can also use video surveillance data to analyze traffic patterns in real-time and ensure tellers are in the right places during peak hours to reduce wait times.
3. On-site data processing
Because the financial services industry is so highly regulated, banks must follow strict security and privacy protocols to protect consumer data from malicious third parties. Transmitting sensitive financial data to the cloud or data center for processing increases the risk of interception and makes it more challenging to meet compliance requirements for data access logging and security controls.
Edge computing allows financial institutions to leverage more data on-site, within the network security perimeter. For example, loan applications contain a lot of sensitive and personally identifiable information (PII). Processing these applications on-site significantly reduces the risk of third-party interception and allows banks to maintain strict control over who accesses data and why, which is more difficult in cloud and colocation data center environments.
4. Enhanced AIOps capabilities
Financial institutions use AIOps (artificial intelligence for IT operations) to analyze monitoring data from IT devices, network infrastructure, and security solutions and get automated incident management, root-cause analysis (RCA), and simple issue remediation. Deploying AIOps at the edge provides real-time issue detection and response, significantly shortening the duration of outages and other technology disruptions. It also ensures continuous operation even if an ISP outage or network failure cuts a branch off from the cloud or data center, further helping to reduce disruptions and remote sites.
Additionally, AIOps and other artificial intelligence technology tend to use GPUs (graphics processing units), which are more expensive than CPUs (central processing units), especially in the cloud. Deploying AIOps on small, decentralized, multi-functional edge computing devices can help reduce costs without sacrificing functionality. For example, deploying an array of Nvidia A100 GPUs to handle AIOps workloads costs at least $10k per unit; comparable AWS GPU instances can cost between $2 and $3 per unit per hour. By comparison, a Nodegrid Gate SR costs under $5k and also includes remote serial console management, OOB, cellular failover, gateway routing, and much more.
The benefits of edge computing for banking
Edge computing can help the financial services industry:
- Reduce losses, theft, and crime by leveraging artificial intelligence to analyze real-time video surveillance data.
- Increase branch productivity and revenue with real-time insights from security systems, customer experience data, and network infrastructure.
- Simplify regulatory compliance by keeping sensitive customer and financial data on-site within company-owned infrastructure.
- Improve resilience with real-time AIOps capabilities like automated incident remediation that continues operating even if the site is cut off from the WAN or Internet
- Reduce the operating costs of AI and machine learning applications by deploying them on small, multi-function edge computing devices.
- Mitigate the risk of interception by leveraging financial and IT data on the local network and distributing the attack surface.
Edge computing best practices
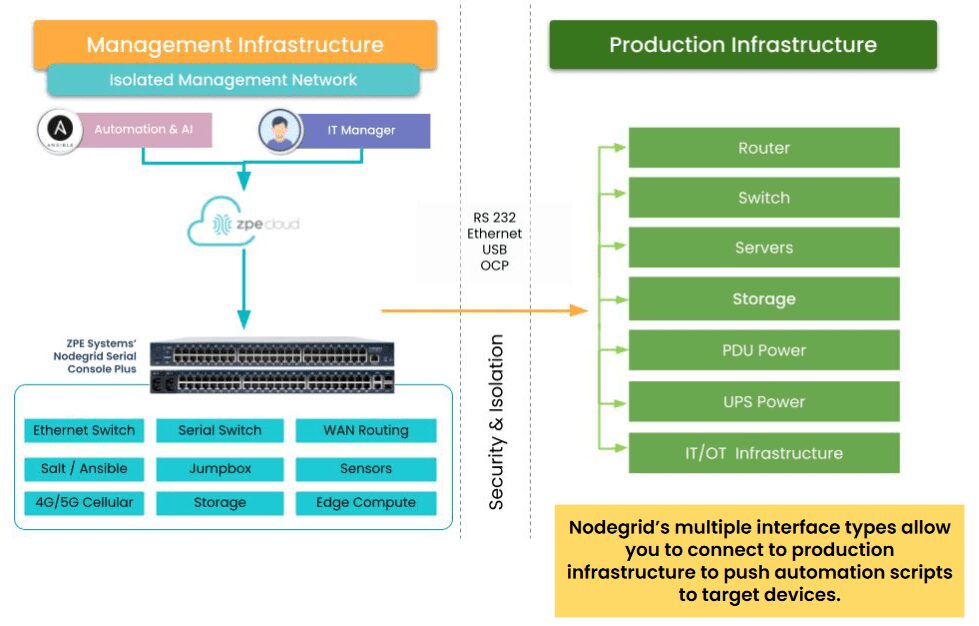
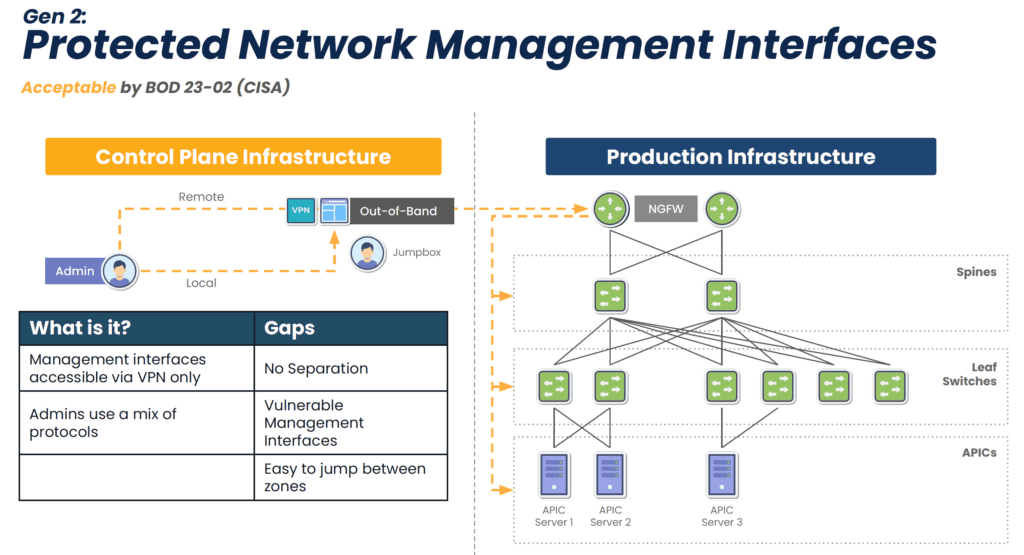
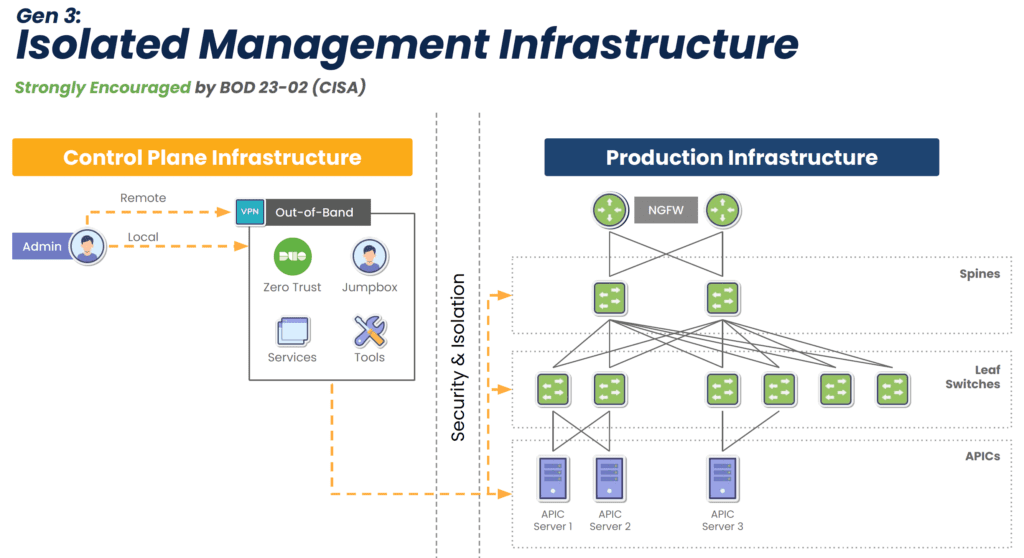
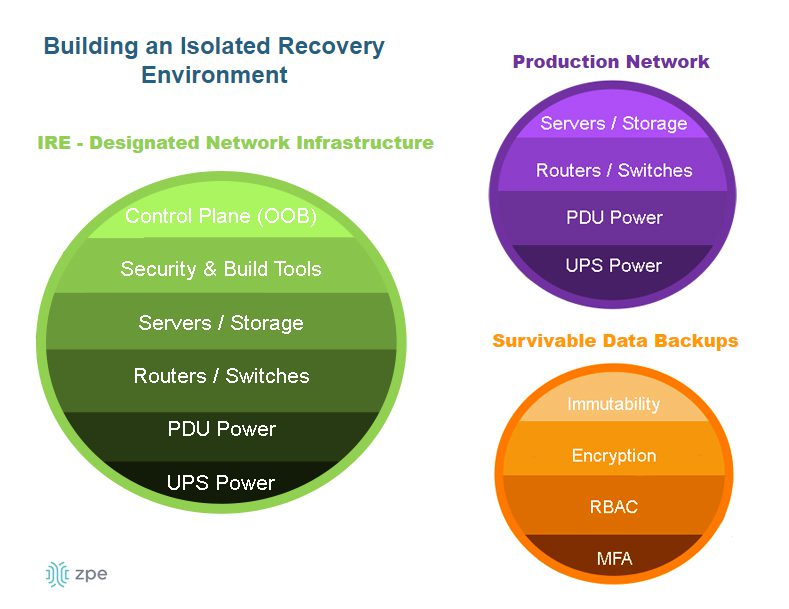
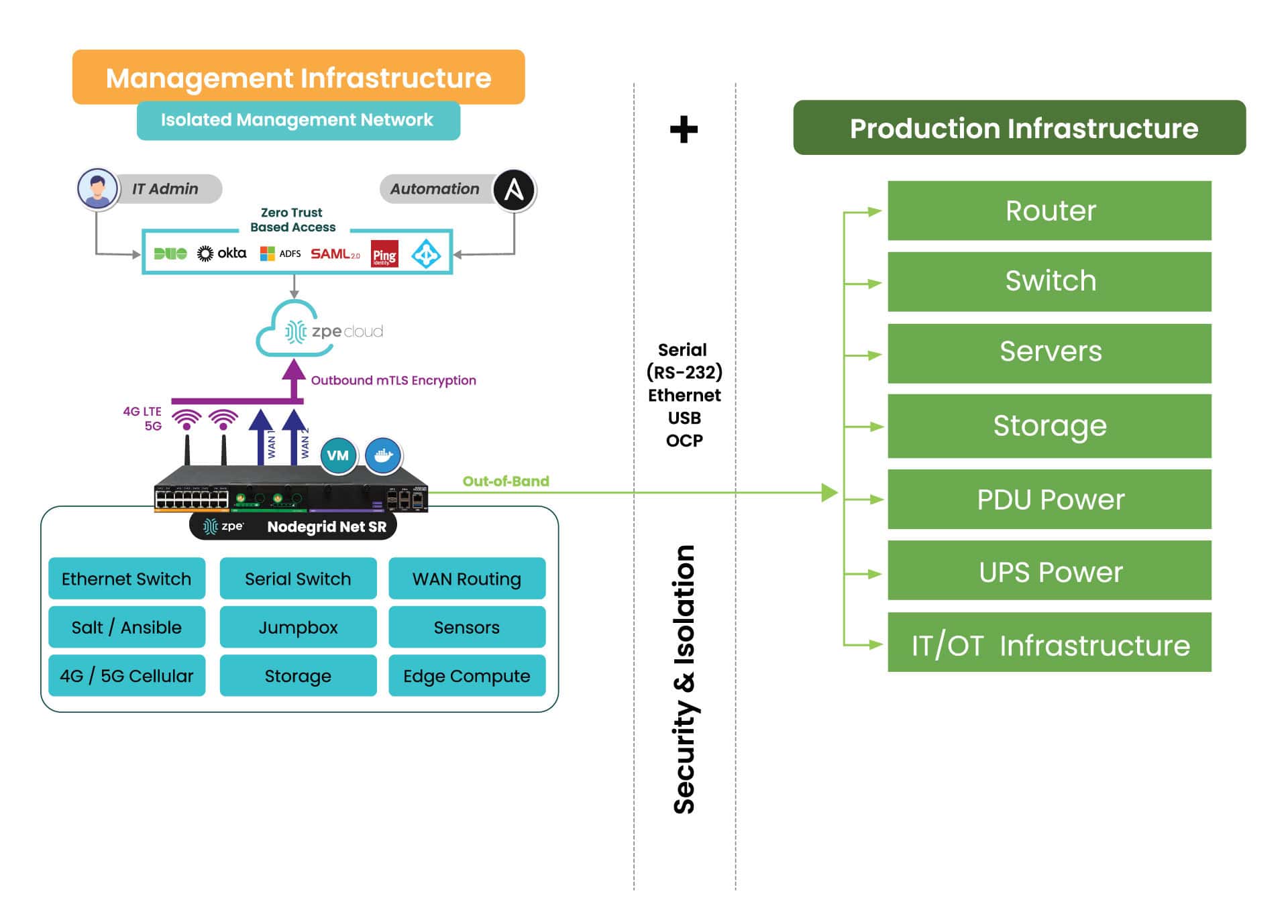
Isolating the management interfaces used to control network infrastructure is the best practice for ensuring the security, resilience, and efficiency of edge computing deployments. CISA and PCI DSS 4.0 recommend implementing isolated management infrastructure (IMI) because it prevents compromised accounts, ransomware, and other threats from laterally moving from production resources to the control plane.
")
Using vendor-neutral platforms to host, connect, and secure edge applications and workloads is the best practice for ensuring the scalability and flexibility of financial edge architectures. Moving away from dedicated device stacks and taking a “platformization” approach allows financial institutions to easily deploy, update, and swap out applications and capabilities on demand. Vendor-neutral platforms help reduce hardware overhead costs to deploy new branches and allow banks to explore different edge software capabilities without costly hardware upgrades.

Additionally, using a centralized, cloud-based edge management and orchestration (EMO) platform is the best practice for ensuring remote teams have holistic oversight of the distributed edge computing architecture. This platform should be vendor-agnostic to ensure complete coverage over mixed and legacy architectures, and it should use out-of-band (OOB) management to provide continuous remote access to edge infrastructure even during a major service outage.
How Nodegrid streamlines edge computing for the banking industry
Nodegrid is a vendor-neutral edge networking platform that consolidates an entire edge tech stack into a single, cost-effective device. Nodegrid has a Linux-based OS that supports third-party VMs and Docker containers, allowing banks to run edge computing workloads, data analytics software, automation, security, and more.
The Nodegrid Gate SR is available with an Nvidia Jetson Nano card that’s optimized for artificial intelligence workloads. This allows banks to run AI surveillance software, ML-powered recommendation engines, and AIOps at the edge alongside networking and infrastructure workloads rather than purchasing expensive, dedicated GPU resources. Plus, Nodegrid’s Gen 3 OOB management ensures continuous remote access and IMI for improved branch resilience.
Get Nodegrid for your edge computing use cases in banking
Nodegrid’s flexible, vendor-neutral platform adapts to any use case and deployment environment. Watch a demo to see Nodegrid’s financial network solutions in action.
")