Improving Your Zero Trust Security Posture
")
The current cyber threat landscape is daunting, with attacks occurring so frequently that security experts recommend operating under the assumption that your network is already breached. Major cyber attacks – and the disruptions they cause – frequently make news headlines. The MGM hack, LendingTree breach, and CDK Global attack are just a few examples that affected thousands of people per incident and now have many organizations rethinking their resilience strategies.
The zero trust security methodology outlines the best practices for limiting the blast radius of a successful breach by preventing malicious actors from moving laterally through the network and accessing the most valuable or sensitive resources. Many organizations have already begun their zero trust journey by implementing role-based access controls (RBAC), multi-factor authentication (MFA), and other security solutions, but still struggle with coverage gaps that result in ransomware attacks and other disruptive breaches. This blog provides advice for improving your zero trust security posture with a multi-layered strategy that mitigates weaknesses for complete coverage.
How to improve your zero trust security posture
.
Gain a full understanding of your protect surface
Many security strategies focus on defending the network’s “attack surface,” or all the potential vulnerabilities an attacker could exploit to breach the network. However, zero trust is all about defending the “protect surface,” or all the data, assets, applications, and services that an attacker could potentially try to access. The key difference is that zero trust doesn’t ask you to try to cover any possible weakness in a network, which is essentially impossible. Instead, it wants you to look at the resources themselves to determine what has the most value to an attacker, and then implement security controls that are tailored accordingly.
Gaining a full understanding of all the resources on your network can be extraordinarily challenging, especially with the proliferation of SaaS apps, mobile devices, and remote workforces. There are automated tools that can help IT teams discover all the data, apps, and devices on the network. Application discovery and dependency mapping (ADDM) tools help identify all on-premises software and third-party dependencies; cloud application discovery tools do the same for cloud-hosted apps by monitoring network traffic to cloud domains. Sensitive data discovery tools scan all known on-premises or cloud-based resources for personally identifiable information (PII) and other confidential data, and there are various device management solutions to detect network-connected hardware, including IoT devices.
,
Micro-segment your network with micro-perimeters
Micro-segmentation is a cornerstone of zero-trust networks. It involves logically separating all the data, applications, assets, and services according to attack value, access needs, and interdependencies. Then, teams implement granular security policies and controls tailored to the needs of each segment, establishing what are known as micro-perimeters. Rather than trying to account for every potential vulnerability with one large security perimeter, teams can just focus on the tools and policies needed to cover the specific vulnerabilities of a particular micro-segment.
Network micro-perimeters help improve your zero trust security posture with:
- Granular access policies granting the least amount of privileges needed for any given workflow. Limiting the number of accounts with access to any given resource, and limiting the number of privileges granted to any given account, significantly reduces the amount of damage a compromised account (or malicious actor) is capable of inflicting.
- Targeted security controls addressing the specific risks and vulnerabilities of the resources in a micro-segment. For example, financial systems need stronger encryption, strict data governance monitoring, and multiple methods of trust verification, whereas an IoT lighting system requires simple monitoring and patch management, so the security controls for these micro-segments should be different.
- Trust verification using context-aware policies to catch accounts exhibiting suspicious behavior and prevent them from accessing sensitive resources. If a malicious outsider compromises an authorized user account and MFA device – or a disgruntled employee uses their network privileges to harm the company – it can be nearly impossible to prevent data exposure. Context-aware policies can stop a user from accessing confidential resources outside of typical operating hours, or from unfamiliar IP addresses, for example. Additionally, user entity and behavior analytics (UEBA) solutions use machine learning to detect other abnormal and risky behaviors that could indicate malicious intent.
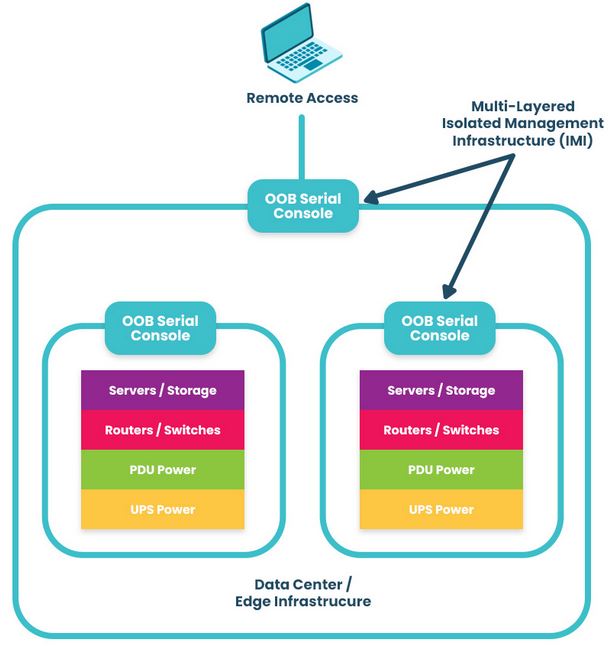
Isolate and defend your management infrastructure
For zero trust to be effective, organizations must apply consistently strict security policies and controls to every component of their network architecture, including the management interfaces used to control infrastructure. Otherwise, a malicious actor could use a compromised sysadmin account to hijack the control plane and bring down the entire network.
According to a recent CISA directive, the best practice is to isolate the network’s control plane so that management interfaces are inaccessible from the production network. Many new cybersecurity regulations, including PCI DSS 4.0, DORA, NIS2, and the CER Directive, also either strongly recommend or require management infrastructure isolation.
Isolated management infrastructure (IMI) prevents compromised accounts, ransomware, and other threats from moving laterally to or from the production LAN. It gives teams a safe environment to recover from ransomware or other cyberattacks without risking reinfection, which is known as an isolated recovery environment (IRE). Management interfaces and the IRE should also be protected by granular, role-based access policies, multi-factor authentication, and strong hardware roots of trust to further mitigate risk.
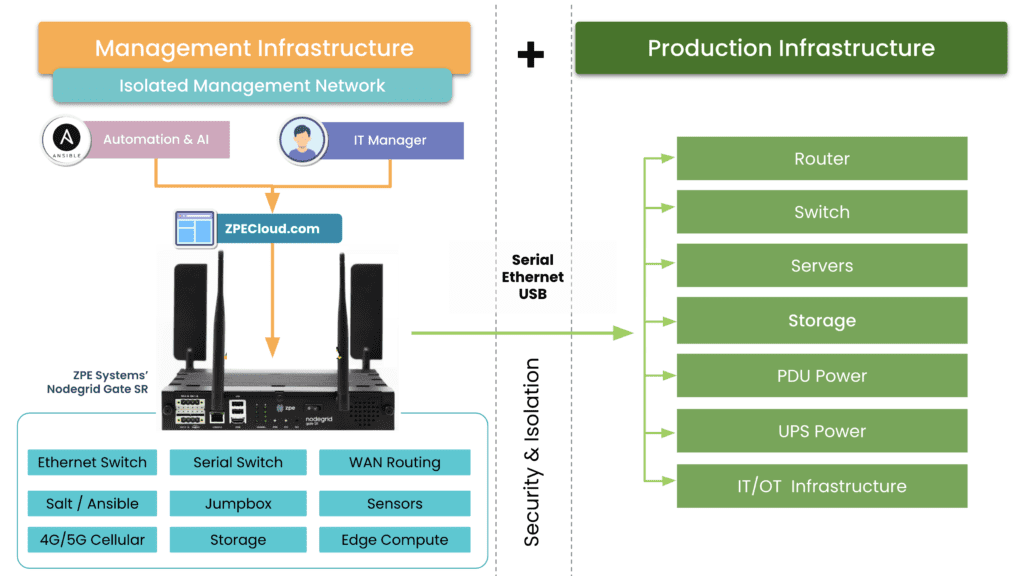
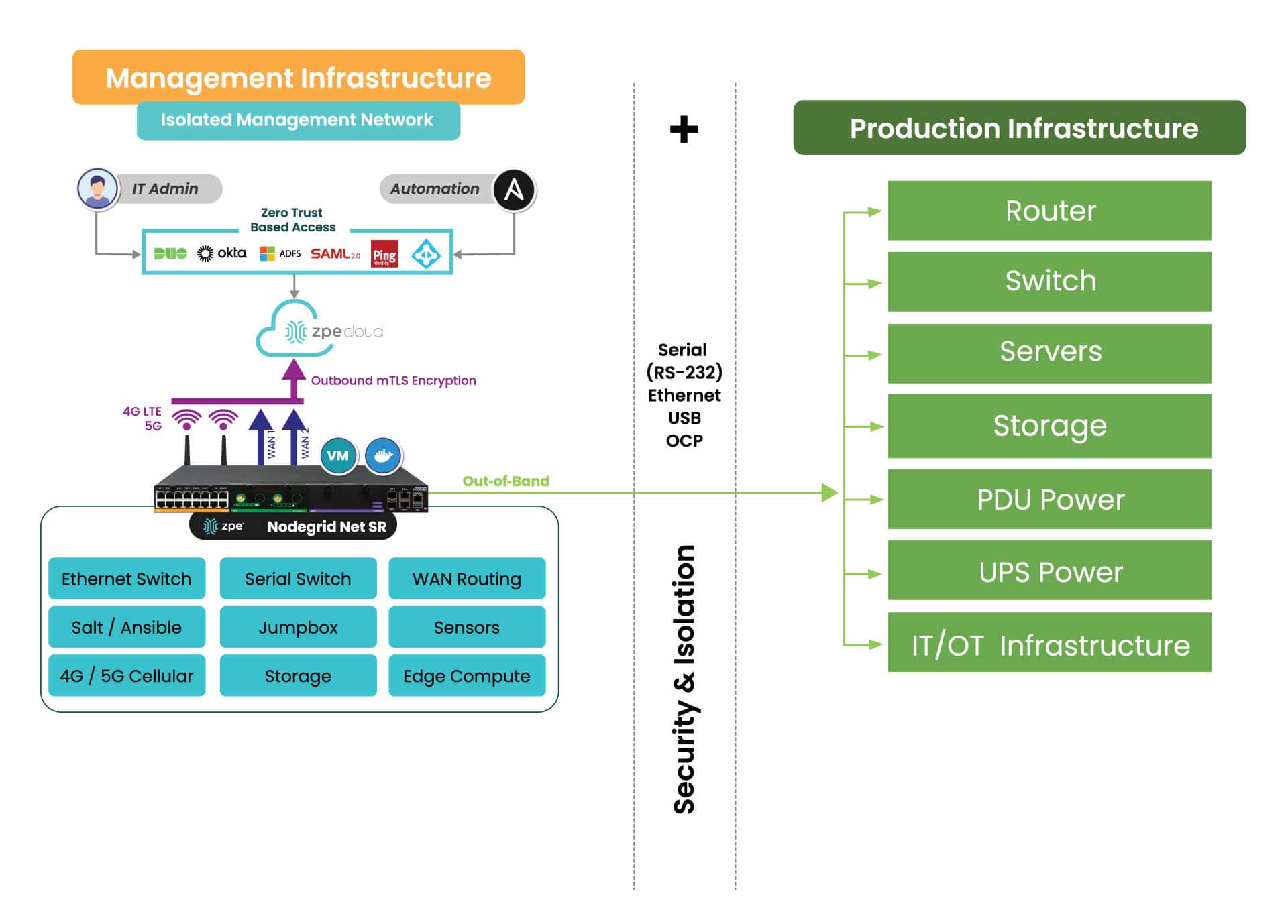 The easiest and most secure way to implement IMI is with Gen 3 out-of-band (OOB) serial console servers, like the Nodegrid solution from ZPE Systems. These devices use alternative network interfaces like 5G/4G LTE cellular to ensure complete isolation and 24/7 management access even during outages. They’re protected by hardware security features like TPM 2.0 and GPS geofencing, and they integrate with zero trust solutions like identity and access management (IAM) and UEBA to enable consistent policy enforcement.
The easiest and most secure way to implement IMI is with Gen 3 out-of-band (OOB) serial console servers, like the Nodegrid solution from ZPE Systems. These devices use alternative network interfaces like 5G/4G LTE cellular to ensure complete isolation and 24/7 management access even during outages. They’re protected by hardware security features like TPM 2.0 and GPS geofencing, and they integrate with zero trust solutions like identity and access management (IAM) and UEBA to enable consistent policy enforcement.
Defend your cloud resources
The vast majority of companies host some or all of their workflows in the cloud, which significantly expands and complicates the attack surface while making it more challenging to identify and defend the protect surface. Some organizations also lack a complete understanding of the shared responsibility model for varying cloud services, increasing the chances of coverage gaps. Additionally, many orgs struggle with “shadow IT,” which occurs when individual business units implement cloud applications without going through onboarding, preventing security teams from applying zero trust controls.
The first step toward improving your zero trust security posture in the cloud is to ensure you understand where your cloud service provider’s responsibilities end and yours begin. For instance, most SaaS providers handle all aspects of security except IAM and data protection, whereas IaaS (Infrastructure-as-a-Service) providers are only responsible for protecting their physical and virtual infrastructure.
It’s also vital that security teams have a complete picture of all the cloud services in use by the organization and a way to deploy and enforce zero trust policies in the cloud. For example, a cloud access security broker (CASB) is a solution that discovers all the cloud services in use by an organization and allows teams to monitor and manage security for the entire cloud architecture. A CASB provides capabilities like data governance, malware detection, and adaptive access controls, so organizations can protect their cloud resources with the same techniques used in the on-premises environment.
.
Extend zero trust to the edge
Modern enterprise networks are highly decentralized, with many business operations taking place at remote branches, Internet of Things (IoT) deployment sites, and end-users’ homes. Extending security controls to the edge with on-premises zero trust solutions is very difficult without backhauling all remote traffic through a centralized firewall, which creates bottlenecks that affect performance and reliability. Luckily, the market for edge security solutions is rapidly growing and evolving to help organizations overcome these challenges.
Security Access Service Edge (SASE) is a type of security platform that delivers core capabilities as a managed, typically cloud-based service for the edge. SASE uses software-defined wide area networking (SD-WAN) to intelligently and securely route edge traffic through the SASE tech stack, allowing the application and enforcement of zero trust controls. In addition to CASB and next-generation firewall (NGFW) features, SASE usually includes zero trust network access (ZTNA), which offers VPN-like functionality to connect remote users to enterprise resources from outside the network. ZTNA is more secure than a VPN because it only grants access to one app at a time, requiring separate authorization requests and trust verification attempts to move to different resources.
Accelerating the zero trust journey
Zero trust is not a single security solution that you can implement once and forget about – it requires constant analysis of your security posture to identify and defend weaknesses as they arise. The best way to ensure adaptability is by using vendor-agnostic platforms to host and orchestrate zero trust security. This will allow you to add and change security services as needed without worrying about interoperability issues.
For example, the Nodegrid platform from ZPE Systems includes vendor-neutral serial consoles and integrated branch services routers that can host third-party software such as SASE and NGFWs. These devices also provide Gen 3 out-of-band management for infrastructure isolation and network resilience. Nodegrid protects management interfaces with strong hardware roots-of-trust, embedded firewalls, SAML 2.0 integrations, and other zero trust security features. Plus, with Nodegrid’s cloud-based or on-premises management platform, teams can orchestrate networking, infrastructure, and security workflows across the entire enterprise architecture.
Improve your zero trust security posture with Nodegrid
Using Nodegrid as the foundation for your zero trust network infrastructure ensures maximum agility while reducing management complexity. Watch a Nodegrid demo to learn more.