Why Out-of-Band Management Is Critical to AI Infrastructure

Artificial intelligence is transforming every corner of industry. Machine learning algorithms are optimizing global logistics, while generative AI tools like ChatGPT are reshaping everyday work and communications. Organizations are rapidly adopting AI, with the global AI market expected to reach $826 billion by 2030, according to Statista. While this growth is reshaping operations and outcomes for organizations in every industry, it brings significant challenges for managing the infrastructure that supports AI workloads.
The Rapid Growth of AI Adoption
AI is no longer a technology that lives only in science fiction. It’s real, and it has quickly become crucial to business strategy and the overall direction of many industries. Gartner reports that 70% of enterprise executives are actively exploring generative AI for their organizations, and McKinsey highlights that 72% of companies have already adopted AI in at least one business function.
It’s easy to understand why organizations are rapidly adopting AI. Here are a few examples of how AI is transforming industries:
- Healthcare: AI-driven diagnostic tools have improved disease detection rates by up to 30x, while drug discovery timelines are being slashed from years to months.
- Retail: E-commerce platforms use AI to power personalized recommendations, leading to a revenue increase of 5-25%.
- Manufacturing: AI in predictive maintenance can help increase productivity by 25%, lower maintenance costs by 25%, and reduce machine downtime by 70%.
AI is a powerful tool that can bring profound outcomes wherever it’s used. But it requires a sophisticated infrastructure of power distribution, cooling systems, computing, GPUs, servers, and networking gear, and the challenge lies in managing this infrastructure.
Infrastructure Challenges Unique to AI
AI environments are complex, with workloads that are both resource-intensive and latency-sensitive. This means organizations face several challenges that are unique to AI:
- Skyrocketing Energy Demands: AI racks consume between 40kW and 200kW of power, which is 10x more than traditional IT equipment. Energy efficiency in the AI data center is a top priority, especially as data centers account for 1% of global electricity consumption.
- Cost of Downtime: AI systems are especially vulnerable to interruptions, which can cause a ripple effect and lead to high costs. A single server failure can disrupt entire model training processes, costing enterprises $9,000 per minute in downtime, as estimated by Uptime Institute.
- Cybersecurity Risks: AI processes sensitive data, making AI data centers prime targets for attack. Sophos reports that in 2024, 59% of organizations suffered a ransomware attack, and the average cost to recover (excluding ransom payment) was $2.73 million.
- Operational Complexity: AI environments rely on a diverse set of hardware and software systems. Monitoring and managing these components effectively requires real-time visibility into thermal conditions, humidity, particulates, and other environmental and device-related factors.
The Role of Out-of-Band Management in AI
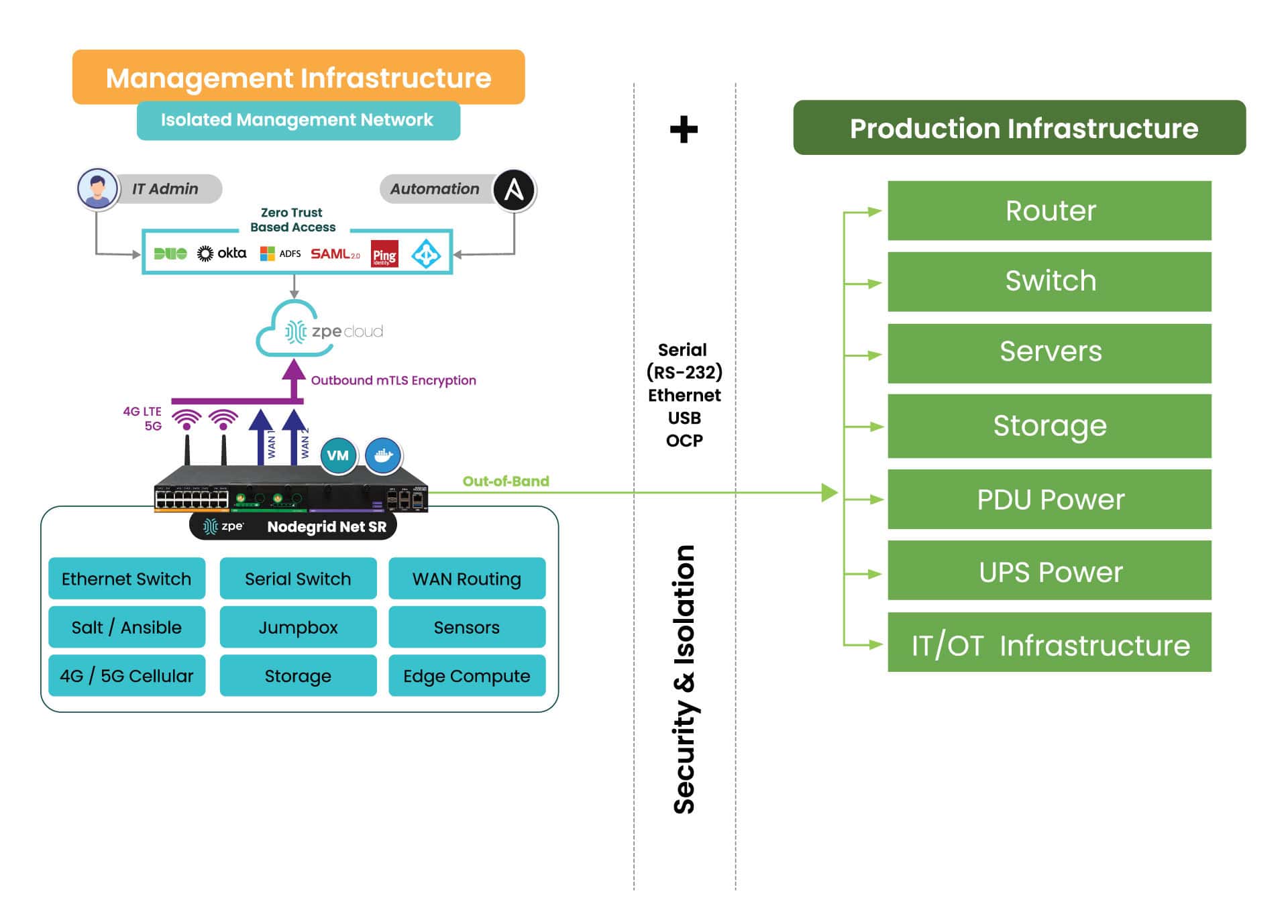
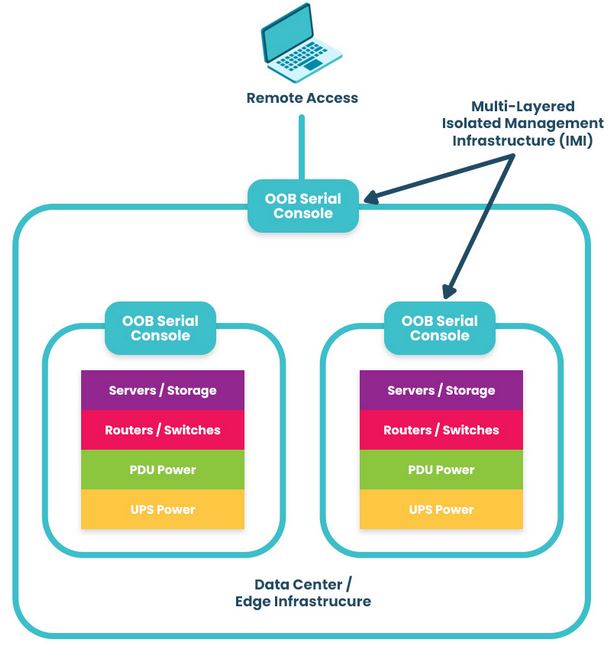
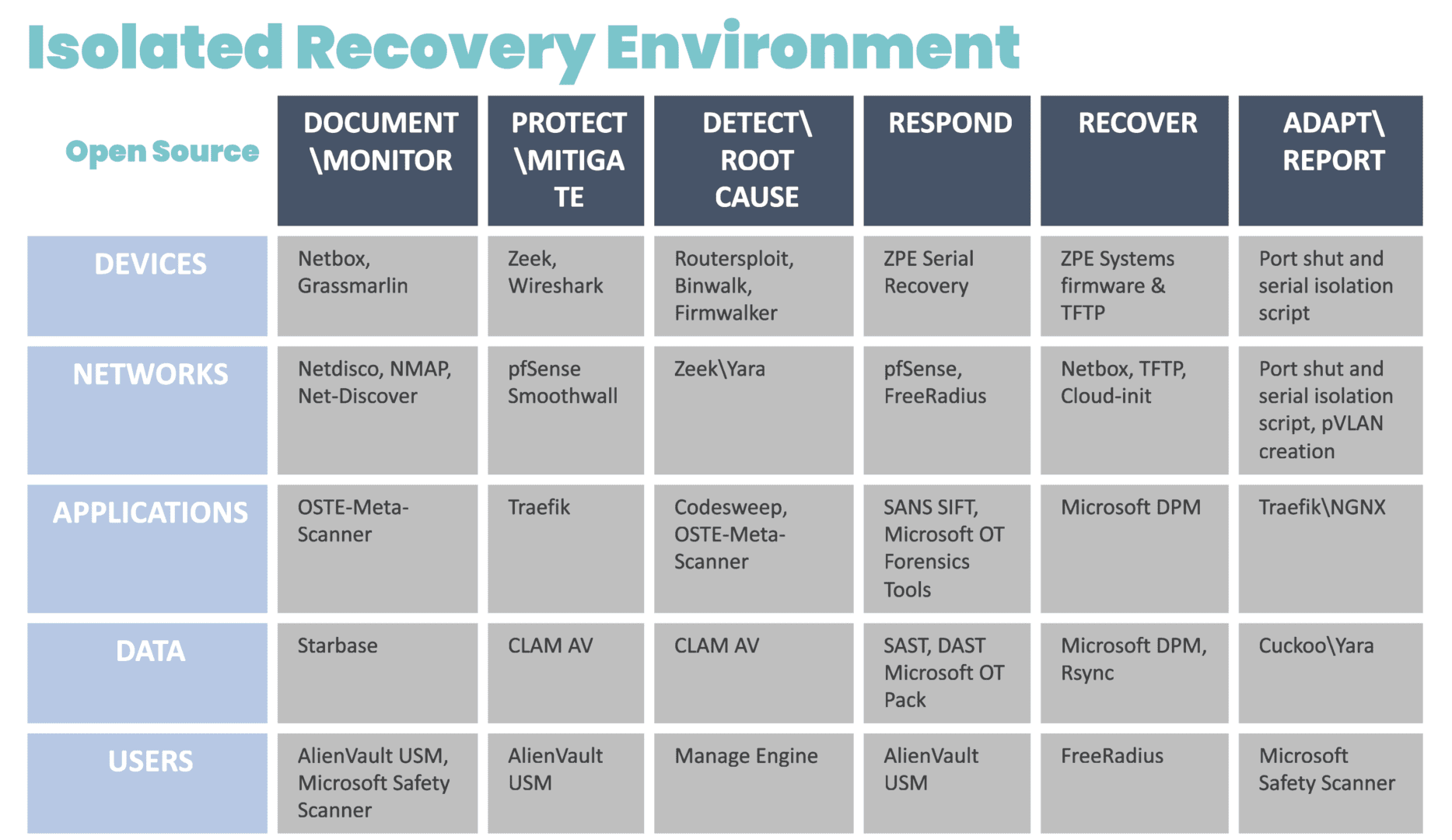
Out-of-band (OOB) management is a must-have for organizations scaling their AI capabilities. Unlike traditional in-band systems that rely on the production network, OOB operates independently to give teams uninterrupted access and control. They can remotely perform monitoring and maintenance tasks to AI infrastructure, troubleshooting, and complete system recovery even if the production network goes offline.
How OOB Management Solves Key Challenges:
- Minimized Downtime: With OOB, IT teams can drastically reduce downtime by troubleshooting issues remotely rather than dispatching teams on-site.
- Energy Efficiency: Real-time monitoring and optimization of power distribution enable organizations to eliminate zombie servers and other inefficiencies.
- Enhanced Security: OOB systems isolate management traffic from production networks per CISA’s best practice recommendations, which reduces the attack surface and mitigates cybersecurity risks.
- Operational Efficiency: Remote monitoring via OOB offers a complete view of environmental conditions and device health, so teams can operate proactively and prevent issues before failures happen.
Use Cases: Out-of-Band Management for AI
There’s no shortage of use cases for AI, but organizations often overlook implementing out-of-band in their environment. Aside from using OOB in AI data centers, here are some real-world use cases of out-of-band management for AI.
1. Autonomous Vehicle R&D
Developers of self-driving technology find it difficult to manage their high-density AI clusters, especially because outages delay testing and development. By implementing OOB management, these developers can reduce recovery times from hours to minutes and shorten development timelines.
2. Financial Services Firms
Banks deploy AI to detect and combat fraud, but these power-hungry systems often lead to inefficient energy usage in the data center. With OOB management, they can gain transparency into GPU and CPU utilization. Not only can they eliminate energy waste, but they can optimize resources to improve model processing speeds.
3. University AI Labs
Universities run AI research on supercomputers, but this strains the underlying infrastructure with high temperatures that can cause failures. OOB management can provide real-time visibility into air temperature, device fan speed, and cooling systems to prevent infrastructure failures.
Download Our Guide, Solving AI Infrastructure Challenges with Out-of-Band Management
Out-of-band management is the key to having reliable, high-performing AI infrastructure. But what does it look like? What devices does it work with? How do you implement it?
Download our whitepaper Solving AI Infrastructure Challenges with Out-of-Band Management for answers. You’ll also get Nvidia’s SuperPOD reference design along with a list of devices that integrate with out-of-band. Click the button for your instant download.