The Future of Data Centers: Overcoming the Challenges of Lights-Out Operations

In a recent article, Y Combinator announced its search for startups aiming to eliminate human intervention in data center development and operation. While one half of this vision seems focused on automating the design and construction of data centers, the other half – focused on fully automating operations (a.k.a. “lights-out”) – is already a reality. ZPE Systems and Legrand are enabling enterprises to achieve this kind of operation by providing the best practices that are already in use in hyperscale data centers for lights-out management.
The Need for Lights-Out Data Centers
The growth of cloud computing, edge deployments, and AI-driven workloads means data centers need to be as efficient, scalable, and resilient as possible. The challenge is that because there is so much infrastructure to manage, the buildout and operation of these data centers becomes very costly and time consuming.
Diane Hu, a YC group partner who previously worked in augmented reality and data science, says, “Hyperscale data center projects take many years to complete. We need more data centers that are created faster and cheaper to build out the infrastructure needed for AI progress. Whether it be in power infrastructure, cooling, procurement of all materials, or project management.”
Dalton Caldwell, a YC managing director who also cofounded App.net, adds, “Software is going to handle all aspects of planning and building a new data center or warehouse. This can include site selection, construction, set up, and ongoing management. They’re going to be what’s called lights-out. There’s going to be robots, autonomously operating 24/7. We want to fund startups to help create this vision.”
In terms of ongoing management and operations, bringing this vision to life will require organizations to overcome several significant problems:
- Rising Operational Costs: Staffing and maintaining on-site engineers 24/7 is costly. Labor expenses, training, and turnover increase operational overhead.
- Human Error and Downtime: Human error is the leading cause of downtime, so having manual processes often leads to costly outages caused by typos, misconfigurations, and slow response times.
- Security Threats: Physical access to data centers increases the risk of insider threats, breaches, and unauthorized interventions.
- Remote Site Management: Managing geographically distributed data centers and edge locations requires staff to be on-site. What’s needed is a scalable and efficient solution that lets staff remotely perform every job, outside of physically installing equipment.
- Sustainability and Energy Efficiency: On-site workers have specific heating/cooling needs that must be met in order to comfortably perform their jobs. Reducing human presence in data centers enables better energy management, which can lower carbon footprints and reduce cooling requirements.
The Roadblocks to Lights-Out Data Centers
Despite the obvious benefits, organizations struggle to implement fully autonomous data center operations. The obstacles include:
- Legacy Infrastructure: Many enterprises still rely on outdated equipment that lacks the necessary integrations for automation and remote control. Adding functions or capabilities typically means deploying more physical boxes, which increases costs and complexity.
- Network Resilience and Connectivity: Traditional in-band network management fails during outages, making it difficult to troubleshoot and recover remotely. Without complete separation of the management network from production networks, organizations are unable to achieve true resilience from errors, outages, and breaches.
- Integration Challenges: Implementing AI-driven automation, OOB management, and cybersecurity protections requires seamless interoperability between different vendors’ solutions.
- Security Concerns: A fully automated data center must have robust access controls, zero-trust security frameworks, and remote threat mitigation capabilities.
- Skill Gaps: The shift to automation necessitates retraining IT staff, who may be unfamiliar with the latest technologies required to maintain a hands-off data center.
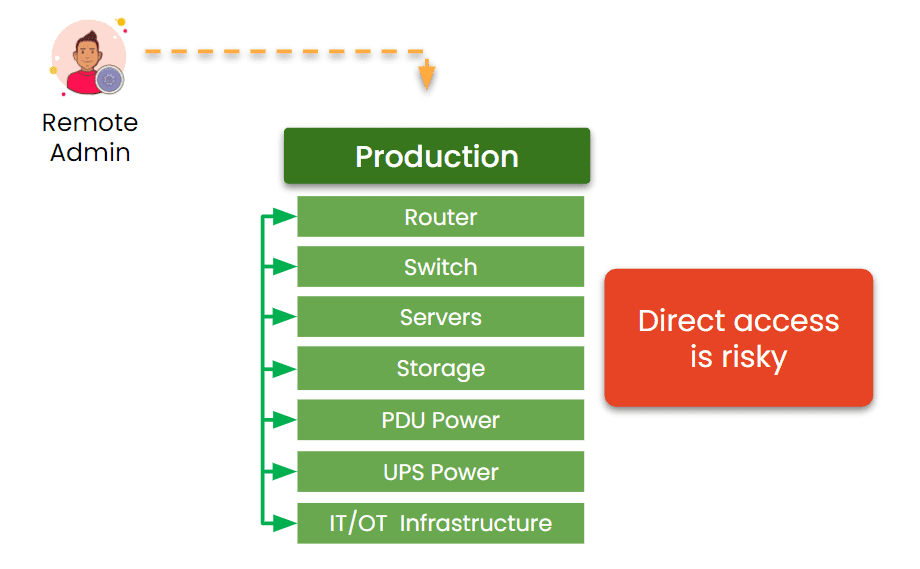
Image: The traditional management approach relies on production assets. This makes it impossible to achieve resilience, because production failures cut off remote admin access.
How ZPE Systems is Powering Lights-Out Operations
ZPE Systems is already helping companies overcome these challenges and transition to lights-out data center operations. As part of Legrand, ZPE is a key component in a total solution offering that includes everything from cabinets and containment to power distribution and remote access. By leveraging out-of-band management, intelligent automation, and zero-trust security, ZPE enables enterprises to manage their infrastructure remotely and securely.
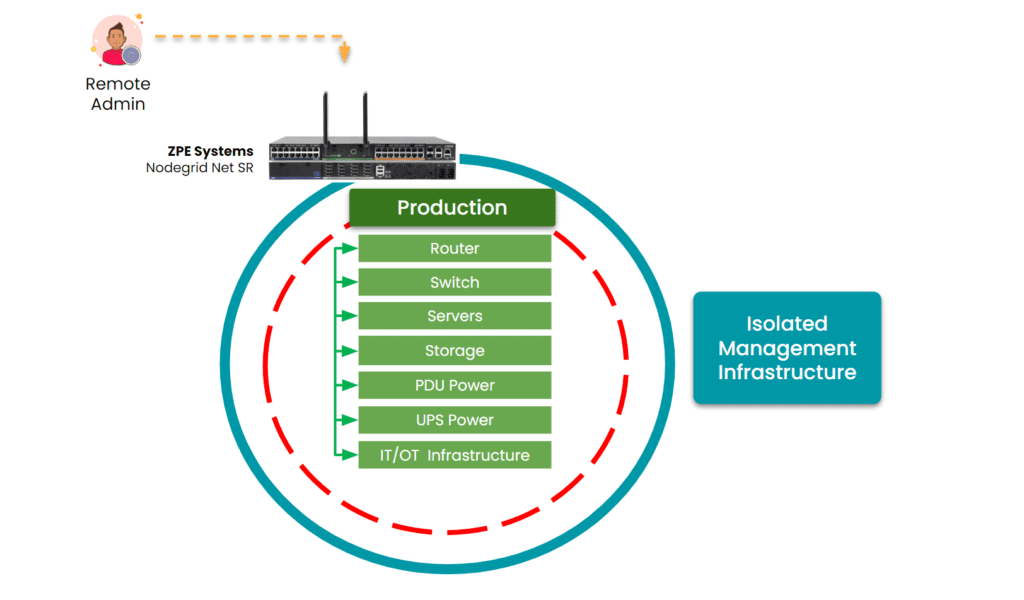
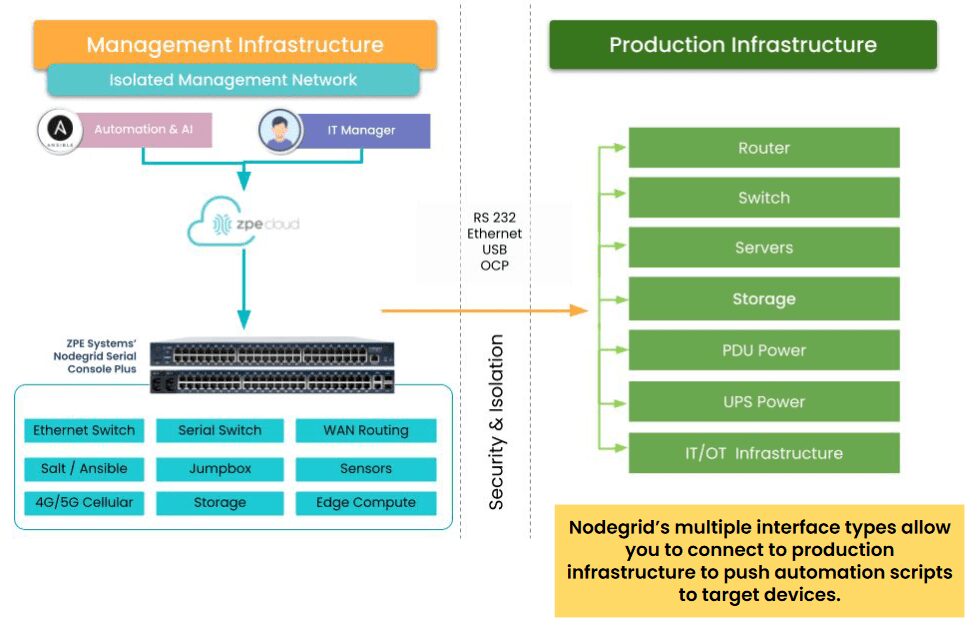
Image: ZPE Systems’ Nodegrid creates an Isolated Management Infrastructure. This gives admins secure remote access, even when the production network fails or suffers an attack.
Key benefits of this management infrastructure include:
- Reliable Remote Access: ZPE’s OOB solutions ensure secure access to critical infrastructure even when primary networks fail. This is made possible by ZPE’s Isolated Management Infrastructure (IMI), which creates a fully separate management network. This single-box solution helps organizations achieve lights-out operations without device sprawl.
- Automated Remediation: ZPE’s platform hosts third party applications, Docker containers, and AI and automation solutions. Organizations can leverage data about device health, telemetry, environmentals, and in-band performance, to resolve issues fast and prevent downtime.
- Hardened Security: ZPE’s solutions are built with security in mind, from local MFA, to self-encrypted disk and signed OS. ZPE also has the most security certifications and validations, including SOC2 Type 2, FIPS 140-3, and ISO27001. Read our full supply chain security assurance pdf.
- Multi-Vendor Integration: ZPE is the only drop-in solution that works across diverse environments, regardless of which vendor solutions are already in place. This makes it easy to deploy IMI and the resilience architecture necessary for achieving lights-out operations.
- Comprehensive Data Center Solutions: With Legrand’s full suite of data center infrastructure, organizations benefit from a fully integrated approach that ensures efficiency, scalability, and resilience.
Lights-out data centers are an achievable reality. By addressing the key challenges and leveraging advanced remote management solutions, enterprises can reduce operational costs, enhance security, and improve efficiency. As part of Legrand, ZPE Systems continues to lead the charge in enabling this transformation for organizations across the globe.
See How Vapor IO Achieved Lights-Out Operations with ZPE Systems
Vapor IO is re-architecting the internet. They deploy micro data centers at the network edge, serving markets across the U.S. and Europe. When they needed to achieve true lights-out operations, they chose ZPE Systems’ Nodegrid. Find out how this solution reduced deployment times to just one hour and delivered additional time and cost savings. Download the full case study below.

Get in Touch for a Demo of Lights-Out Data Center Operations
Our engineers are ready to walk you through lights-out operations. Click below to set up a demo.



")


")