When IT Goes Dark: What I Wish I Knew 20 Years Ago

“No one ever tells you this part…”
My name is Ahmed Algam. I am a Network & Systems Administrator for ZPE Systems – A Brand of Legrand, with over 20 years of experience in network administration, system infrastructure, Microsoft ERP solutions, and enterprise IT management. I have a B.S. in Computer Science and will soon complete my Master’s of Information and Data Science.
In the early days of my IT career, I learned how to build systems from scratch, configure networks, and apply patches.
Like many, I was trained to focus on the obvious goals: keep things running, keep everything secure, and automate what I can.
But what no one taught me? What to do when everything goes dark – literally.
That’s exactly what happened recently.
ZPE’s Fremont branch lost power unexpectedly and without notice from our provider.
One by one, our services went down
- ESXi Hosts
- Backup Servers
- VPN Tunnels
- Core Routers and Switches
Here is the part that I wish I knew 20 years ago…
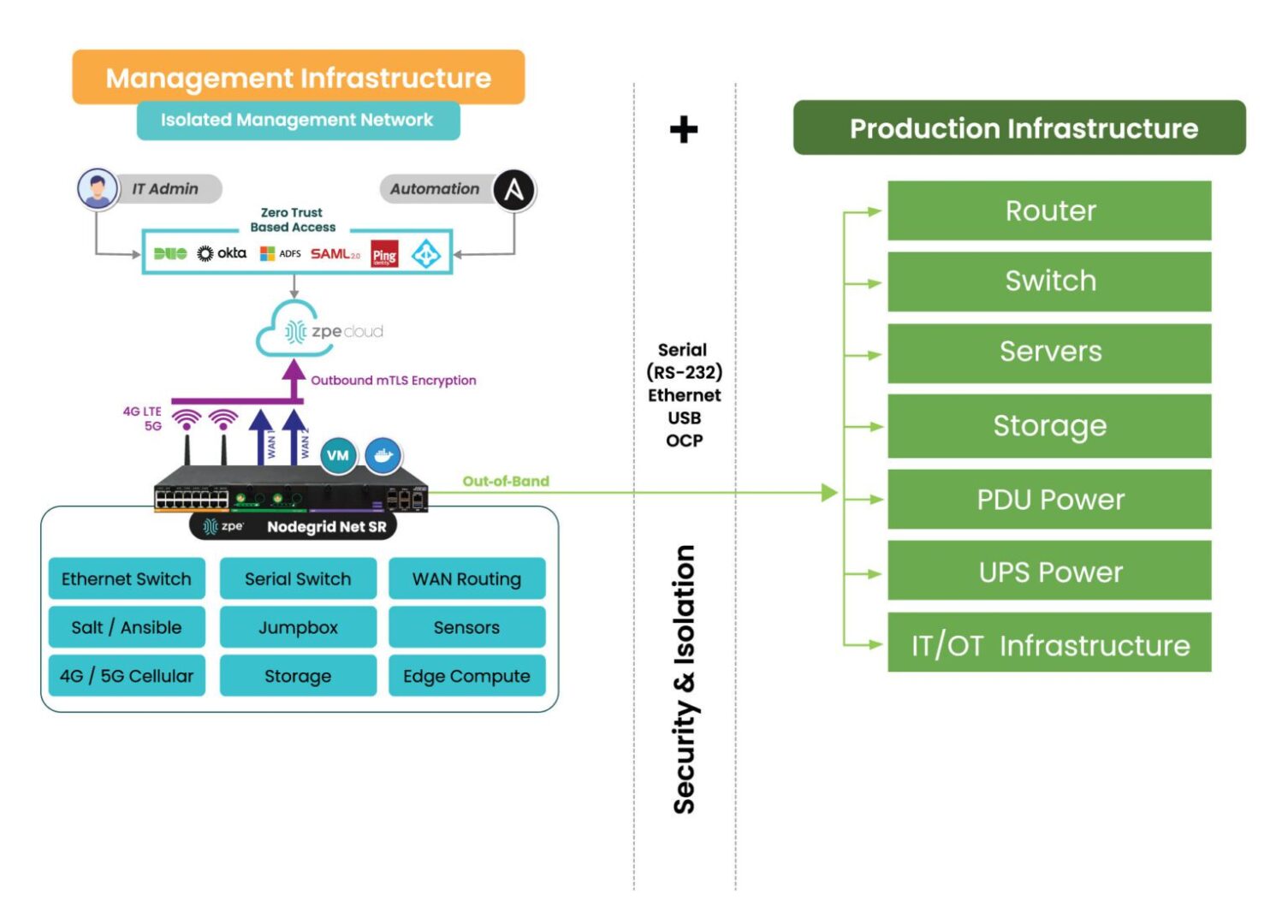
You won’t be rescued by dashboards, spreadsheets, or documentation when IT goes dark. What WILL save you is system design, specifically out-of-band management.
And for which I am lucky that design did save us.
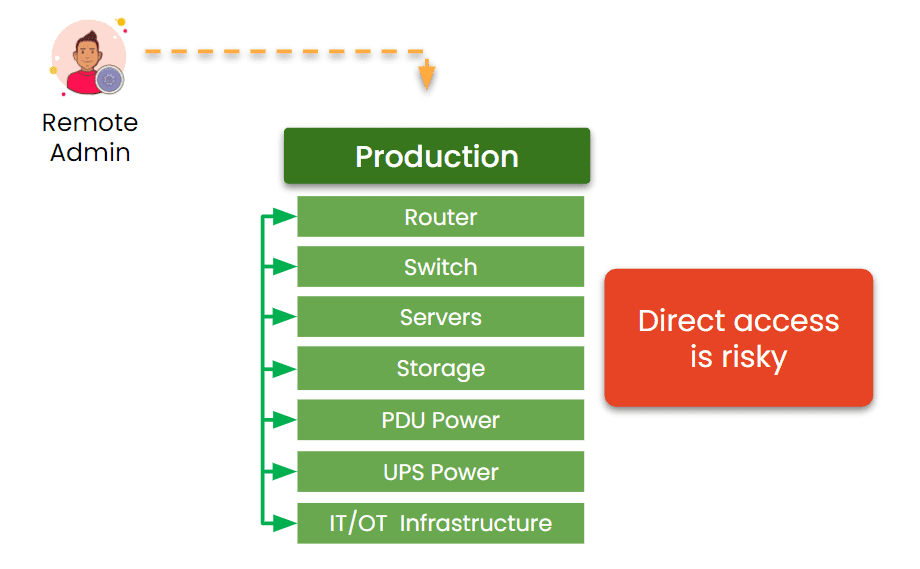
Without Out-of-band (OOB), I would have had to spend the whole night at the office manually rebooting, configuring, and troubleshooting everything. It’s a nightmare for IT admins because you might get the call while you’re attending your kids’ sporting events, attending college courses, or spending quality time with your family. IT emergencies can really intrude on your life outside of work. It’s just part of the job.
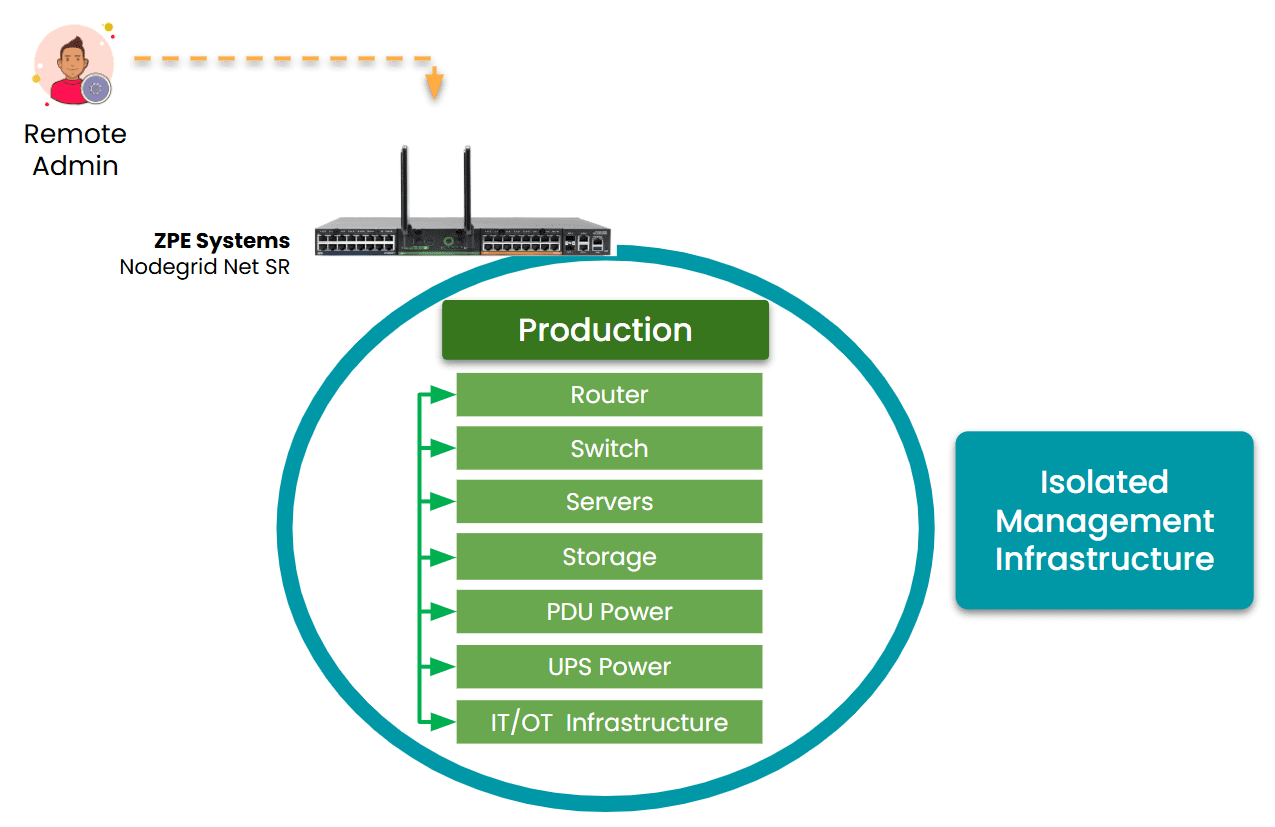
But I was so grateful to have OOB because it gave me a separate path dedicated to recovery, which was just what I needed. I was able to instantly remote-into my infrastructure without leaving home.

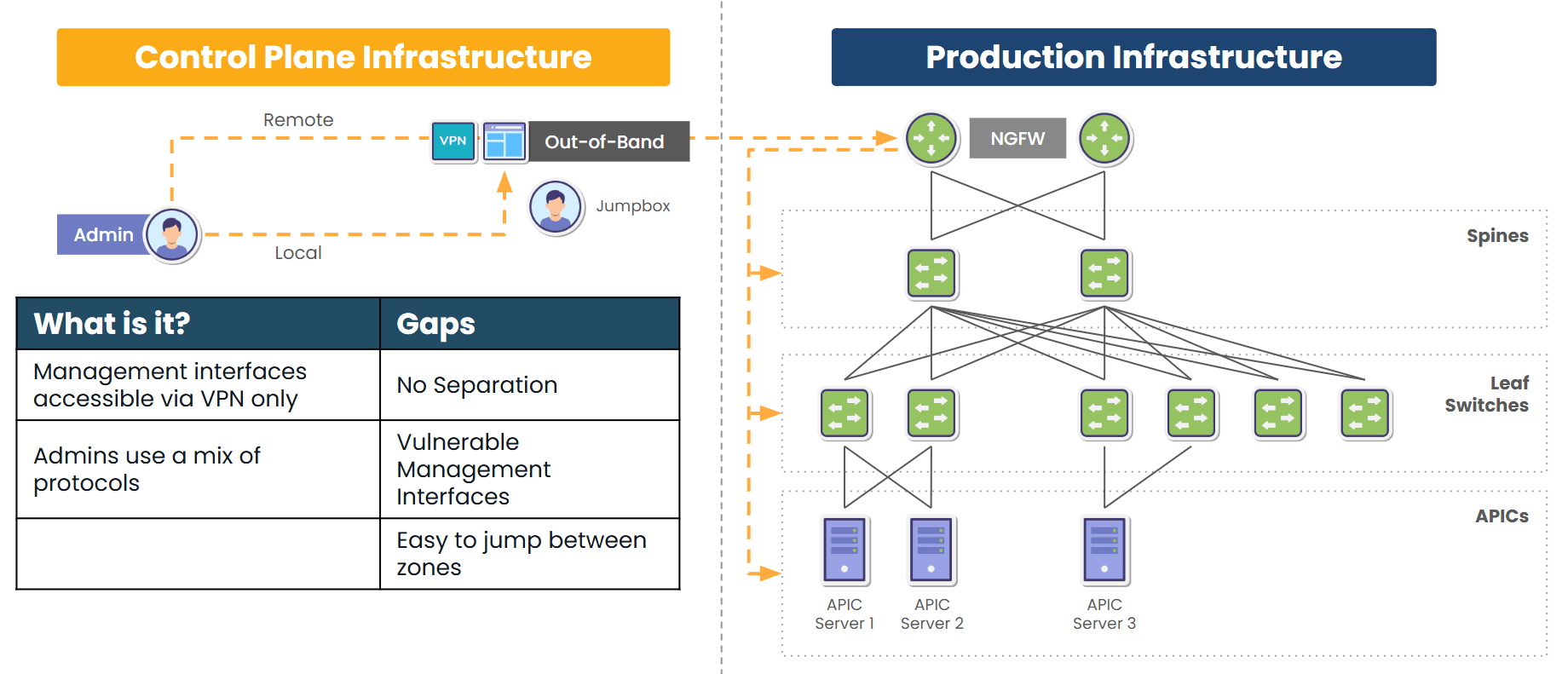
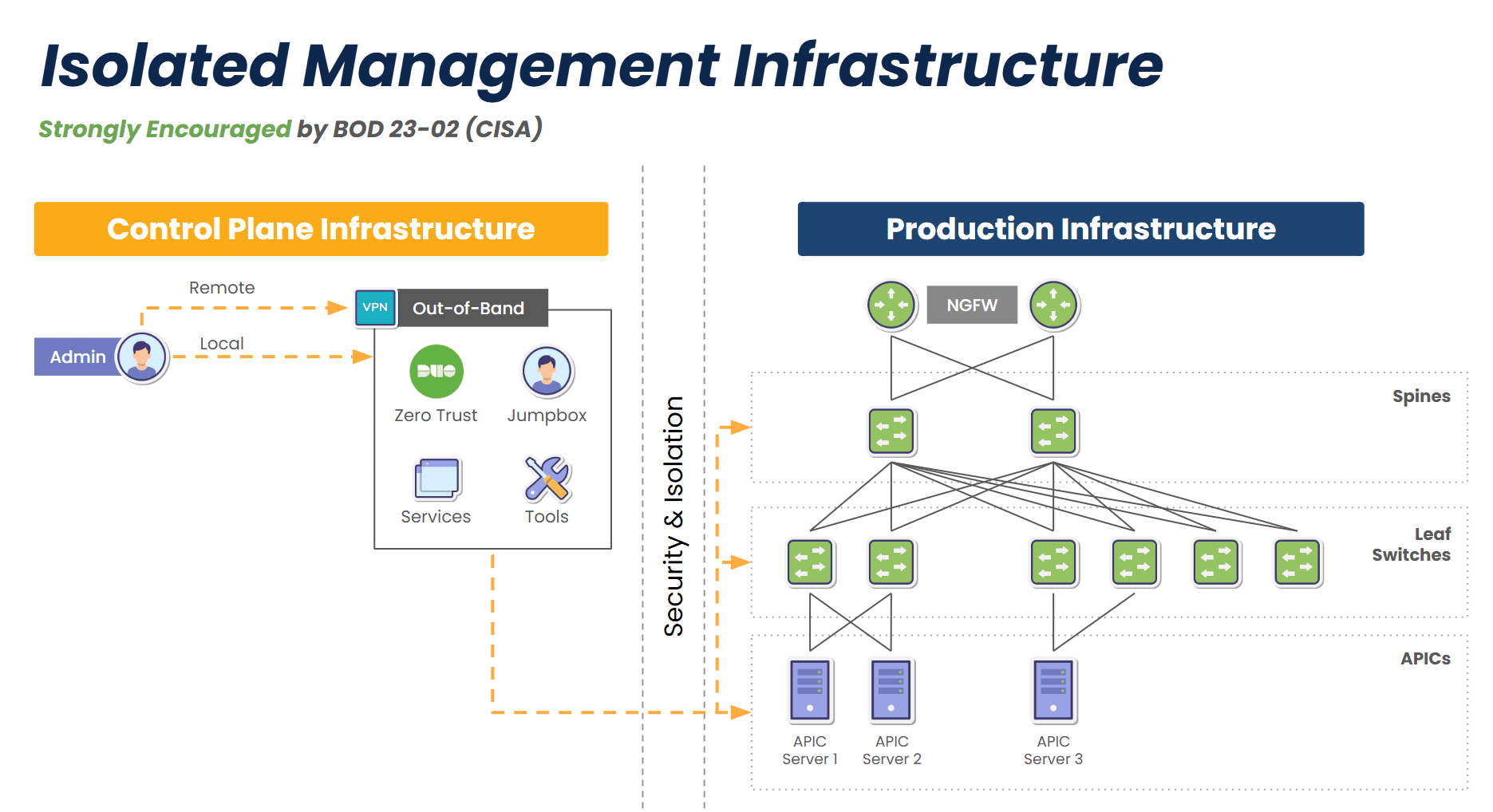
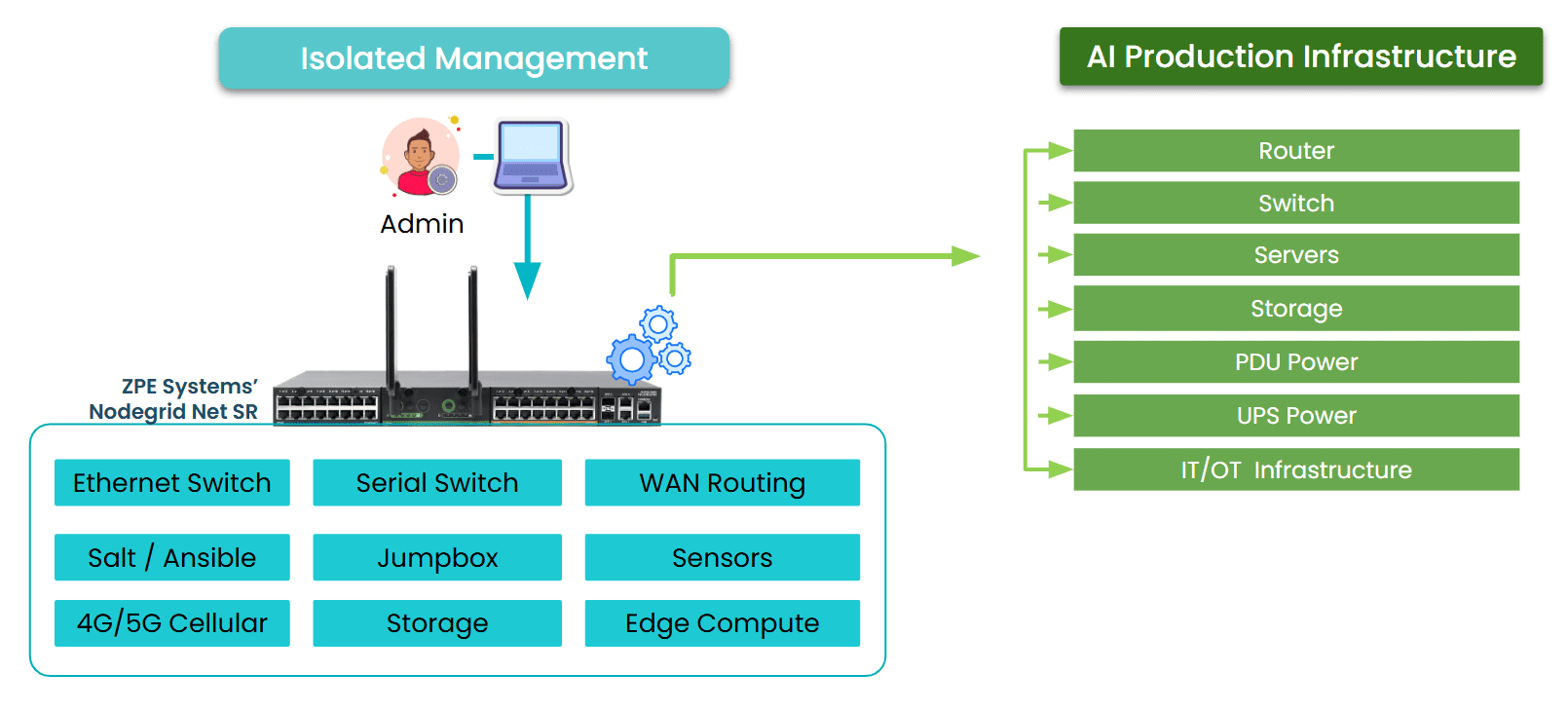
Image: Isolated Management Infrastructure uses out-of-band management (OOBM) serial consoles to access production devices when they are offline.
Within minutes, I was able to:
- Remotely connect through our OOB console
- Restart critical infrastructure
- Monitor recovery independently of the production path
I didn’t have to head for the office or change the plans I had with my family. With our OOB system in place, I knew that I could fix the problem, have services restored before sunrise, and still get a good night’s sleep.
This wasn’t luck
It was the result of:
- Planning for the worst-case scenario, not just the routine
- Having OOB in all essential areas
- Testing access methods instead of assuming they’ll just work
- Separating management traffic from production flows
- Staying calm with an architecture designed to withstand chaos
Even highly-skilled IT teams come to a full standstill during disruptions
It has nothing to do with a lack of talent or skill. The reason is their inability to access the malfunctioning systems.
So here’s my advice to every IT professional:
- Now is the time to prepare for the worst
- Make an OOB network
- Separate management paths from production (and test access!)
Because when the lights go out, that’s when real IT begins.

Here’s How You Can Set Up Out-of-Band Management
My colleagues recently created this guide on how to set up an out-of-band network using Starlink. It includes technical wiring diagrams and a guided walkthrough.
You can download it here: How to Build Out-of-Band With Starlink
Discover More OOB and IMI Resources
-
- What is Network Management?
- Cloud Repatriation: Why Companies are Moving Back to On-Prem
- Why AI System Reliability Depends on Secure Remote Network Management
- Comparing The Best Out-of-Band Management Devices
- Video: ZPE Cloud demo presented by Marcel van Zwienen
- Case study: Re-architecting the internet with Vapor IO
- Out-of-Band Deployment Guide