Out-of-Band vs. Isolated Management Infrastructure: What’s the Difference?

What is Out-of-Band Management?
Out-of-Band Management has been around for decades. It gives IT administrators remote access to network equipment through an independent channel, serving as a lifeline when the primary network is down.
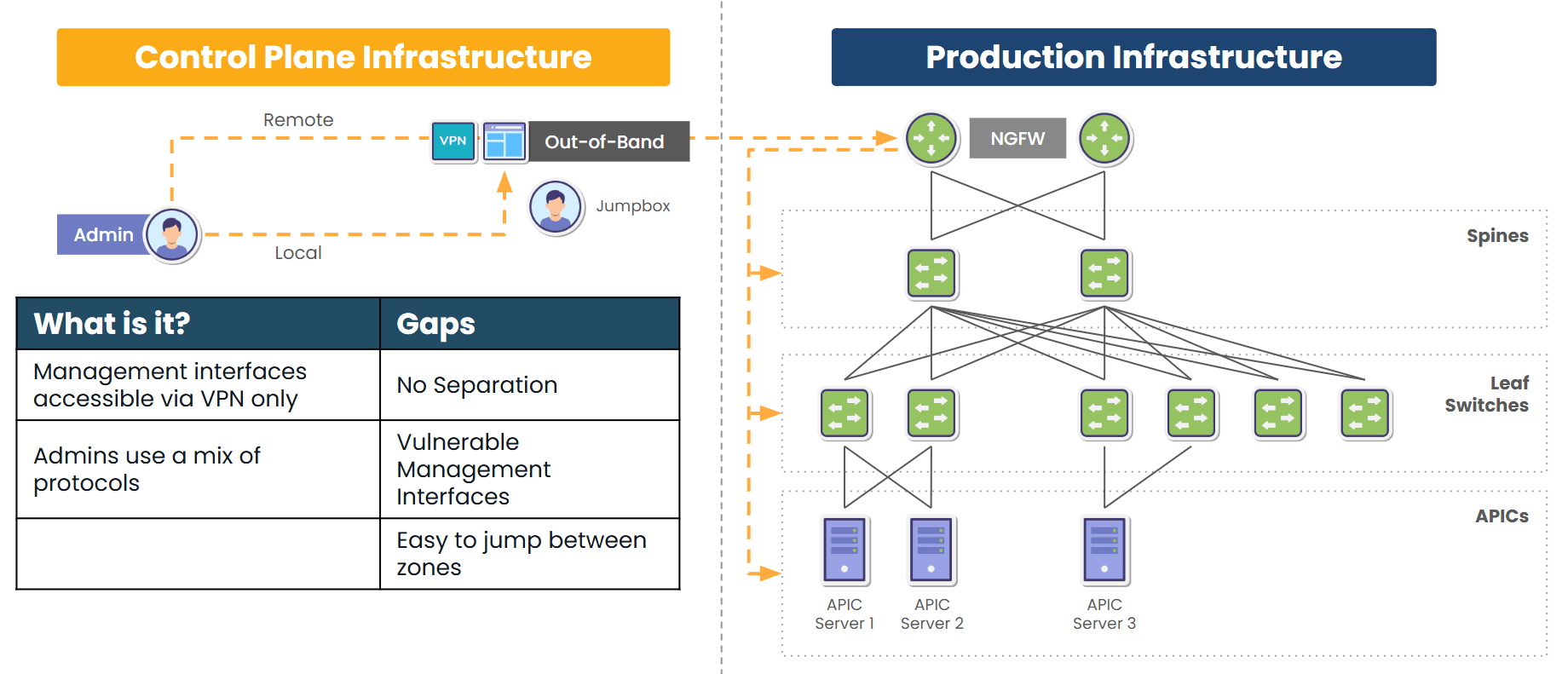
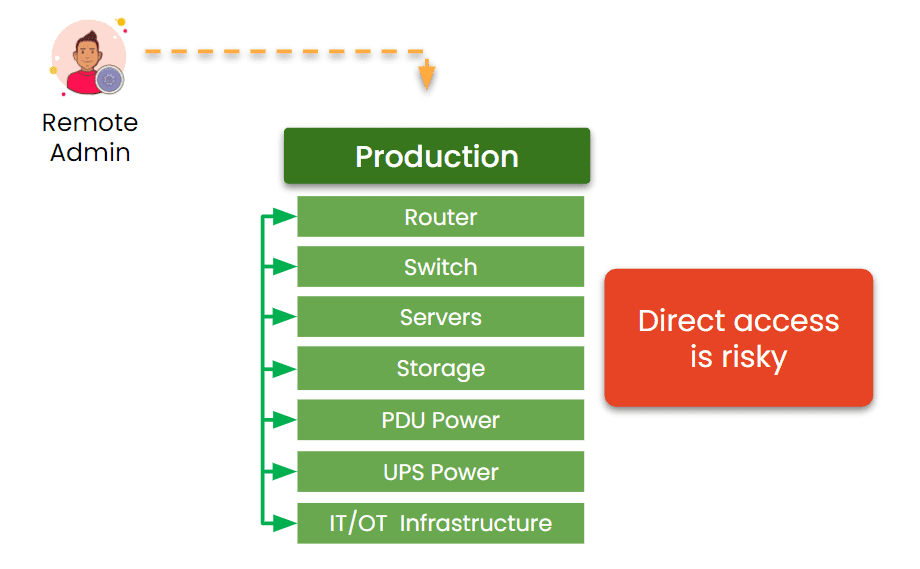
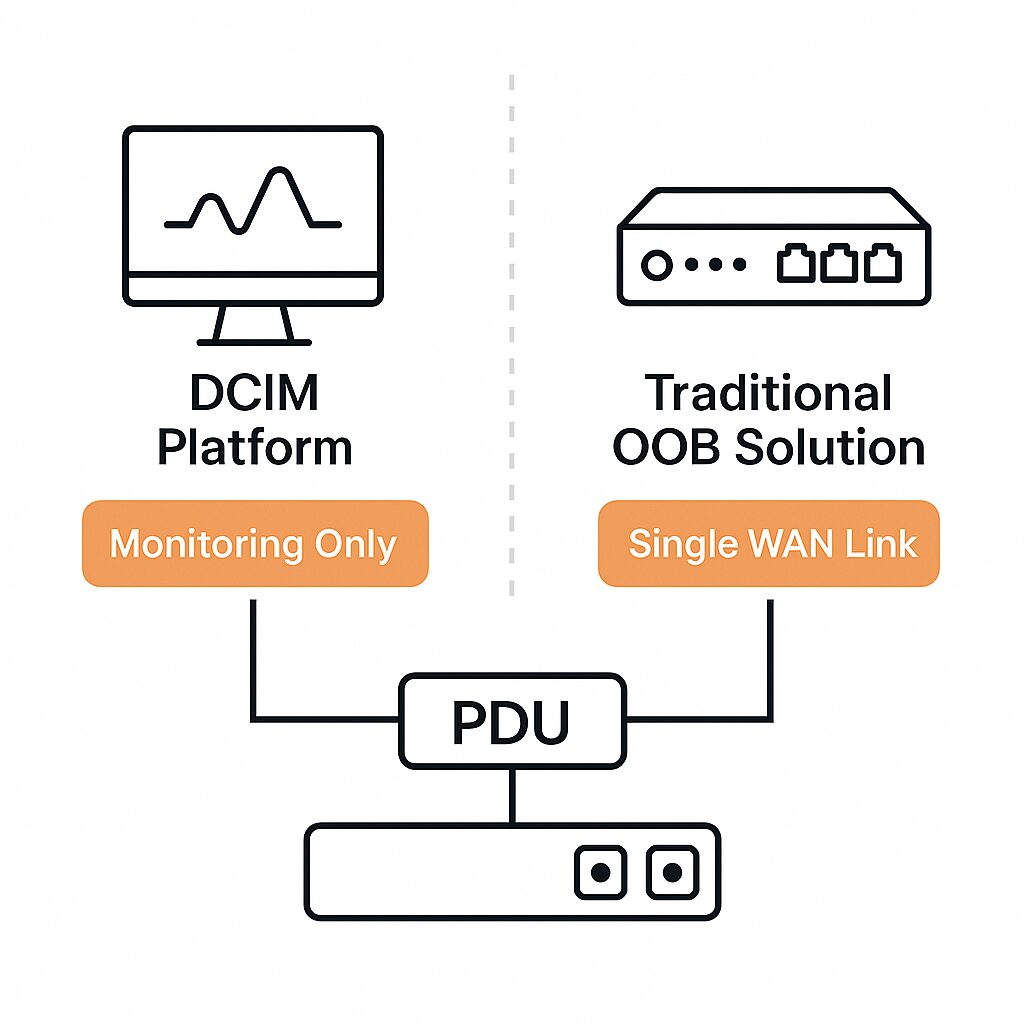
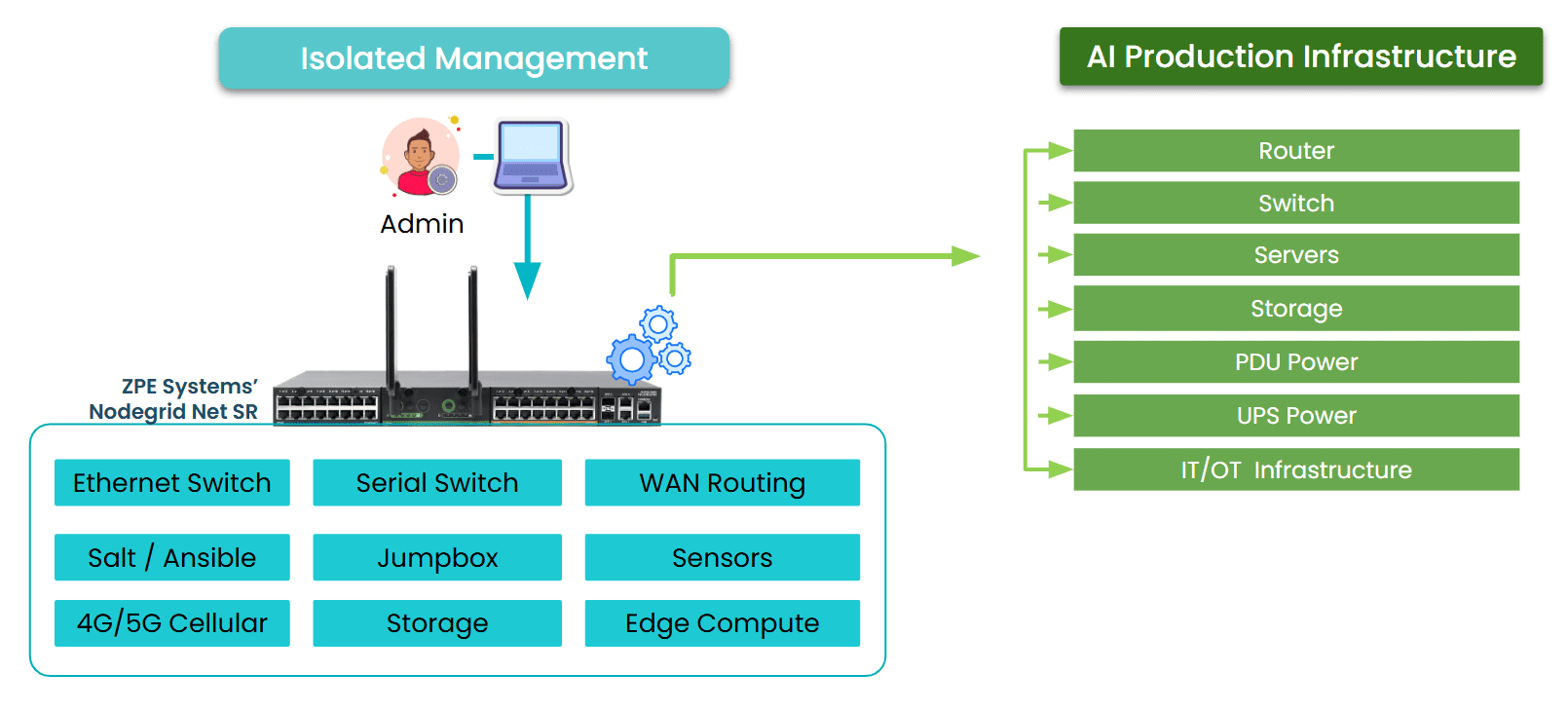
Image: Traditional out-of-band solutions provide a secondary path to production infrastructure, but still rely in part on production equipment.
Most OOB solutions are like a backup entrance: if the main network is compromised, locked, or unavailable, OOB provides a way to “go around the front door” and fix the problem from the outside.
Key Characteristics:
- Separate Path: Usually uses dedicated serial ports, USB consoles, or cellular links.
- Primary Use Cases: Though OOB can be used for regular maintenance and updates, it’s typically used for emergency access, remote rebooting, BIOS/firmware-level diagnostics, and sometimes initial provisioning.
- Tools Involved: Console servers, terminal servers, or devices with embedded OOB ports (e.g., BMC/IPMI for servers).
Business Impact:
From a business standpoint, traditional OOB solutions offer reactive resilience that helps resolve outages faster and without costly site visits. It also reduces Mean Time to Repair (MTTR) and enhances the ability to manage remote or unmanned locations.
However, solutions like ZPE Systems’ Nodegrid provide robust capability that evolves out-of-band to a new level. This comprehensive, next-gen OOB is called Isolated Management Infrastructure.
What is Isolated Management Infrastructure?
Isolated Management Infrastructure furthers the concept of resilience and is a natural evolution of out-of-band. IMI does two things:
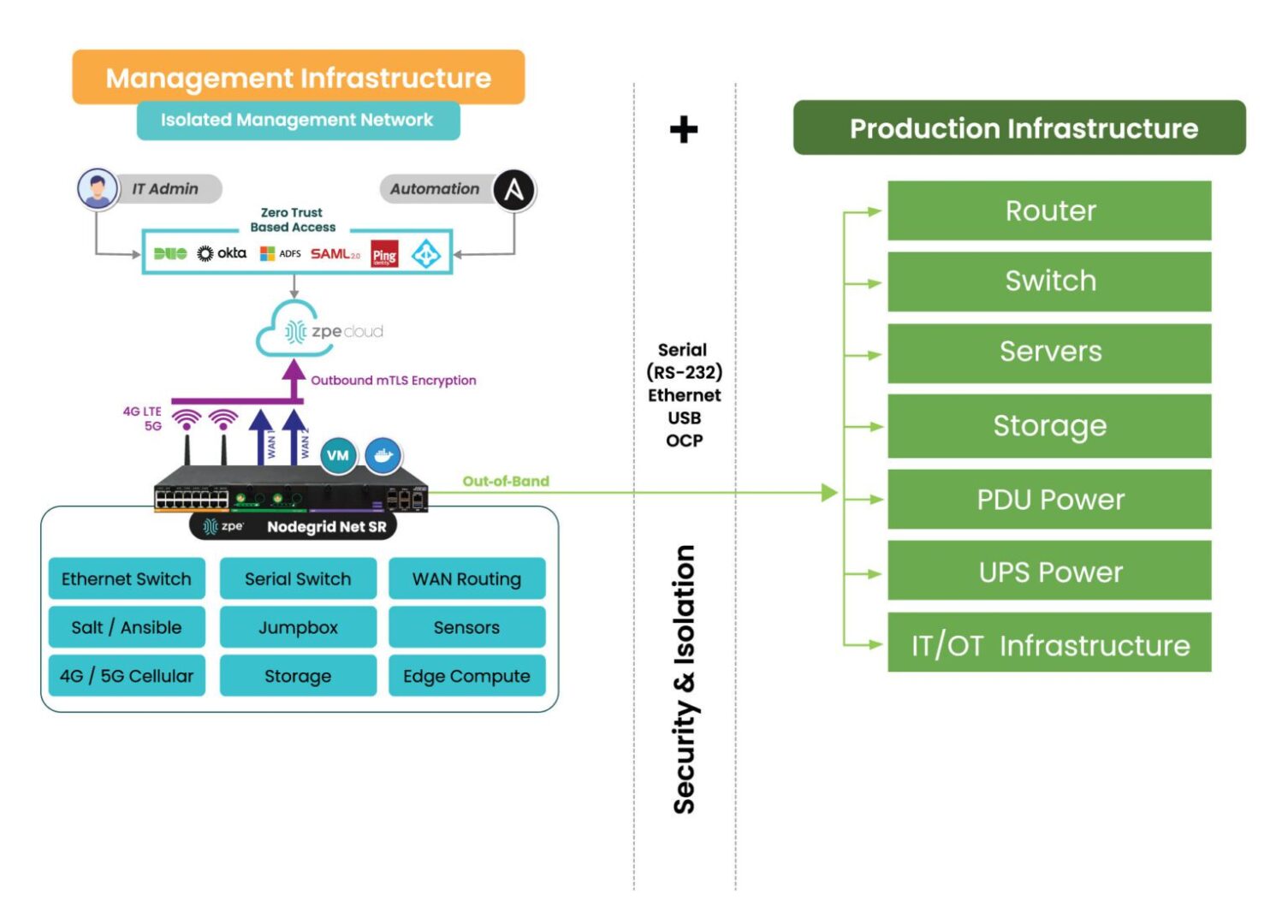
- Rather than just providing a secondary path into production devices, IMI creates a completely separate management plane that does not rely on any production device.
- IMI incorporates its own switches, routers, servers, and jumpboxes to support additional critical IT functions like networking, computing, security, and automation.
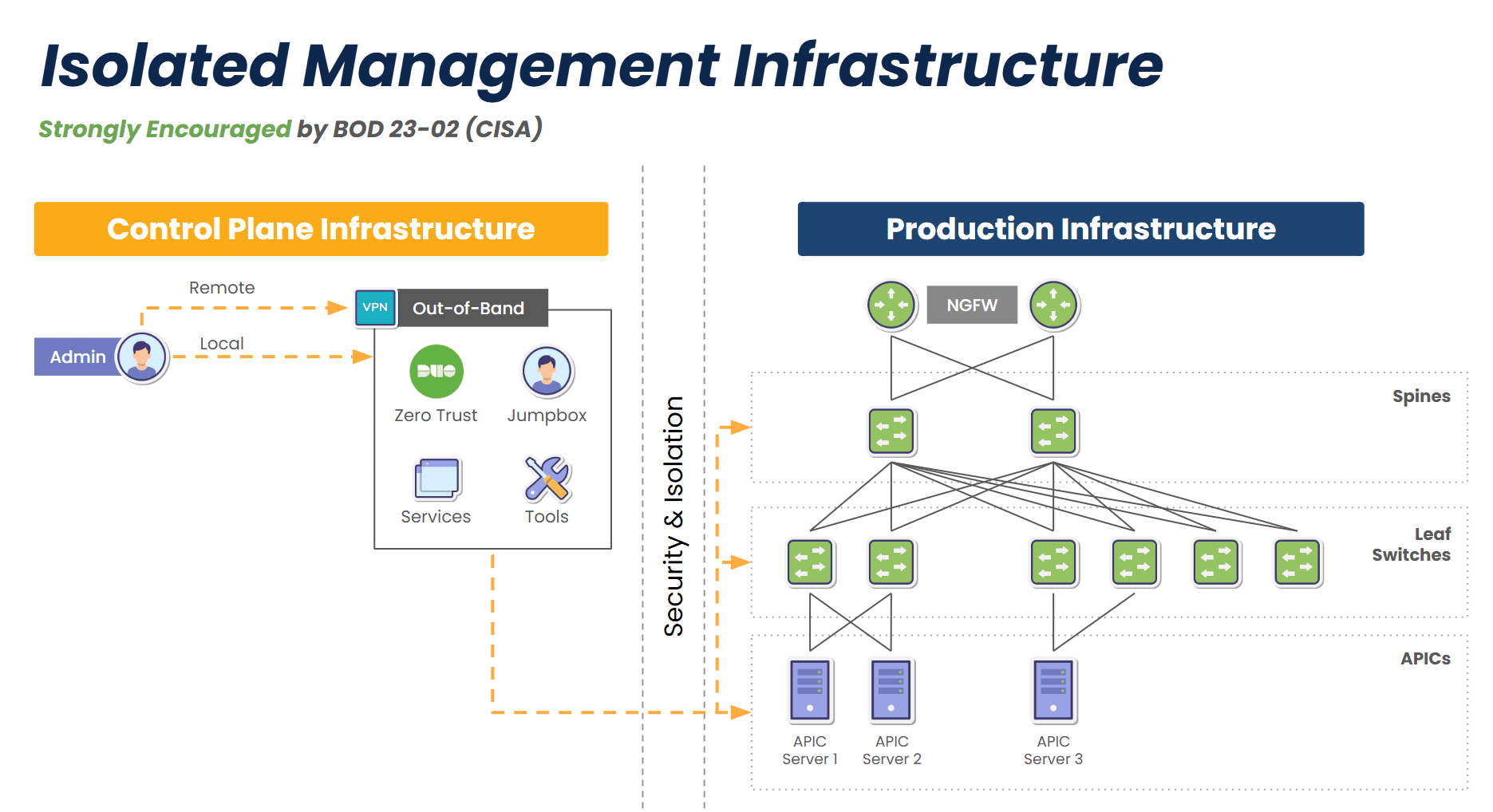
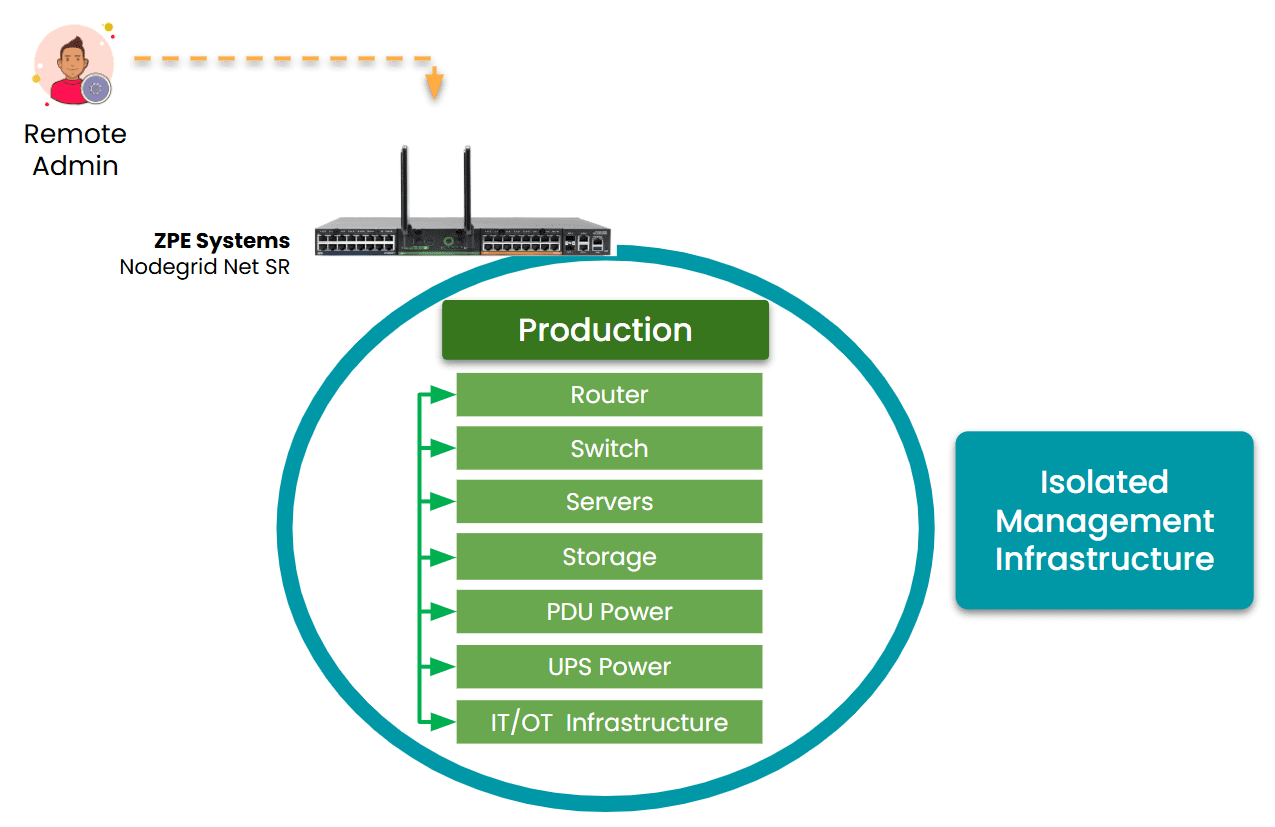
Image: Isolated Management Infrastructure creates a completely separate management plane and full-stack platform for maintaining critical services even during disruptions, and is strongly encouraged by CISA BOD 23-02.
IMI doesn’t just provide access during a crisis – it creates a separate layer of control and serves as a resilience system that keeps core services running no matter what. This gives organizations proactive resilience from simple upgrade errors and misconfigurations, to ransomware attacks and global disruptions like 2024’s CrowdStrike outage.
Key Characteristics:
- Fully Isolated Design: The management plane is physically and logically isolated from the production network, with console access to all production devices via a variety of interfaces including RS-232, Ethernet, USB, and IPMI.
- Backup Links: Uses two or more backup links for reliable access, such as 5G, Starlink, and others.
- Multi-Functionality: Hosts network monitoring, DNS, DHCP, automation engines, virtual firewalls, and all tools and functions to support critical services during disruptions.
- Automation: Provides a safe environment for teams to build, test, and integrate automation workflows, with the ability to automatically revert back to a golden image in case of errors.
- Ransomware Recovery: Hosts all tools, apps, and services to deploy the Gartner-recommended Secure Isolated Recovery Environments (SIRE).
- Zero Trust and Compliance Ready: Built to minimize blast radius and support regulated environments, with segmentation and zero trust security features such as MFA and Role-Based Access Controls (RBAC).
Business Impact:
IMI enables operational continuity in the face of cyberattacks, misconfigurations, or outages. It aligns with zero-trust principles and regulatory frameworks like NIST 800-207, making it ideal for government, finance, and healthcare. It also provides a foundation for modern DevSecOps and AI-driven automation strategies.
Comparing Reactive vs. Proactive Resilience
Why Businesses Should Care
For CIOs and CTOs
IMI is more than a management tool – it’s a strategic shift in infrastructure design. It minimizes dependency on the production network for critical IT functions and gives teams a layered defense. For organizations using AI, hybrid-cloud architectures, or edge computing, IMI is strongly encouraged and should be incorporated into the initial design.
For Network Architects and Engineers
IMI significantly reduces manual intervention during incidents. Instead of scrambling to access firewalls or core switches when something breaks, teams can rely on an isolated environment that remains fully operational. It also enables advanced automation workflows (e.g., self-healing, dynamic traffic rerouting) that just aren’t possible in traditional OOB environments.
Get a Demo of IMI
Set up a 15-minute demo to see IMI in action. Our experts will show you how to automatically provision devices, recover failed equipment, and combat ransomware. Use the button to set up your demo now.
Watch How IMI Improves Security
Rene Neumann (Director of Solution Engineering) gives a 10-minute presentation on IMI and how it enhances security.

Discover More OOB and IMI Resources
-
- What is Network Management?
- Cloud Repatriation: Why Companies are Moving Back to On-Prem
- Why AI System Reliability Depends on Secure Remote Network Management
- Comparing The Best Out-of-Band Management Devices
- Video: ZPE Cloud demo presented by Marcel van Zwienen
- Case study: Re-architecting the internet with Vapor IO
- Out-of-Band Deployment Guide