Edge Computing Requirements

The Internet of Things (IoT) and remote work capabilities have allowed many organizations to conduct critical business operations at the enterprise network’s edges. Wearable medical sensors, automated industrial machinery, self-service kiosks, and other edge devices must transmit data to and from software applications, machine learning training systems, and data warehouses in centralized data centers or the cloud. Those transmissions eat up valuable MPLS bandwidth and are attractive targets for cybercriminals.
Edge computing involves moving data processing systems and applications closer to the devices that generate the data at the network’s edges. Edge computing can reduce WAN traffic to save on bandwidth costs and improve latency. It can also reduce the attack surface by keeping edge data on the local network or, in some cases, on the same device.
Running powerful data analytics and artificial intelligence applications outside the data center creates specific challenges. For example, space is usually limited at the edge, and devices might be outdoors where power and climate control are more complex. This guide discusses the edge computing requirements for hardware, networking, availability, security, and visibility to address these concerns.
Edge computing requirements
The primary requirements for edge computing are:
1. Compute
As the name implies, edge computing requires enough computing power to run the applications that process edge data. The three primary concerns are:
- Processing power: CPUs (central processing units), GPUs (graphics processing units), or SoCs (systems on chips)
- Memory: RAM (random access memory)
- Storage: SSDs (solid state drives), SCM (storage class memory), or Flash memory
- Coprocessors: Supplemental processing power needed for specific tasks, such as DPUs (data processing units) for AI
The specific edge computing requirements for each will vary, as it’s essential to match the available compute resources with the needs of the edge applications.
2. Small, ruggedized chassis
Space is often quite limited in edge sites, and devices may not be treated as delicately as they would be in a data center. Edge computing devices must be small enough to squeeze into tight spaces and rugged enough to handle the conditions they’ll be deployed in. For example, smart cities connect public infrastructure and services using IoT and networking devices installed in roadside cabinets, on top of streetlights, and in other challenging deployment sites. Edge computing devices in other applications might be subject to constant vibrations from industrial machinery, the humidity of an offshore oil rig, or even the vacuum of outer space.
3. Power
In some cases, edge deployments can use the same PDUs (power distribution units) and UPSes (uninterruptible power supplies) as a data center deployment. Non-traditional implementations, which might be outdoors, underground, or underwater, may require energy-efficient edge computing devices using alternative power sources like batteries or solar.
4. Wired & wireless connectivity
Edge computing systems must have both wired and wireless network connectivity options because organizations might deploy them somewhere without access to an Ethernet wall jack. Cellular connectivity via 4G/5G adds more flexibility and ideally provides network failover/out-of-band capabilities.
5. Out-of-band (OOB) management
Many edge deployment sites don’t have any IT staff on hand, so teams manage the devices and infrastructure remotely. If something happens to take down the network, such as an equipment failure or ransomware attack, IT is completely cut off and must dispatch a costly and time-consuming truck roll to recover. Out-of-band (OOB) management creates an alternative path to remote systems that doesn’t rely on any production infrastructure, ensuring teams have continuous access to edge computing sites even during outages.
6. Security
Edge computing reduces some security risks but can create new ones. Security teams carefully monitor and control data center solutions, but systems at the edge are often left out. Edge-centric security platforms such as SSE (Security Service Edge) help by applying enterprise Zero Trust policies and controls to edge applications, devices, and users. Edge security solutions often need hardware to host agent-based software, which should be factored into edge computing requirements and budgets. Additionally, edge devices should have secure Roots of Trust (RoTs) that provide cryptographic functions, key management, and other features that harden device security.
7. Visibility
Because of a lack of IT presence at the edge, it’s often difficult to catch problems like high humidity, overheating fans, or physical tampering until they affect the performance or availability of edge computing systems. This leads to a break/fix approach to edge management, where teams spend all their time fixing issues after they occur rather than focusing on improvements and innovations. Teams need visibility into environmental conditions, device health, and security at the edge to fix issues before they cause outages or breaches.
Streamlining edge computing requirements
An edge computing deployment designed around these seven requirements will be more cost-effective while avoiding some of the biggest edge hurdles. Another way to streamline edge deployments is with consolidated, vendor-neutral devices that combine core networking and computing capabilities with the ability to integrate and unify third-party edge solutions. For example, the Nodegrid platform from ZPE Systems delivers computing power, wired & wireless connectivity, OOB management, environmental monitoring, and more in a single, small device. ZPE’s integrated edge routers use the open, Linux-based Nodegrid OS capable of running Guest OSes and Docker containers for your choice of third-party AI/ML, data analytics, SSE, and more. Nodegrid also allows you to extend automated control to the edge with Gen 3 out-of-band management for greater efficiency and resilience.
Want to learn more about how Nodegrid makes edge computing easier and more cost-effective?
To learn more about consolidating your edge computing requirements with the vendor-neutral Nodegrid platform, schedule a free demo!

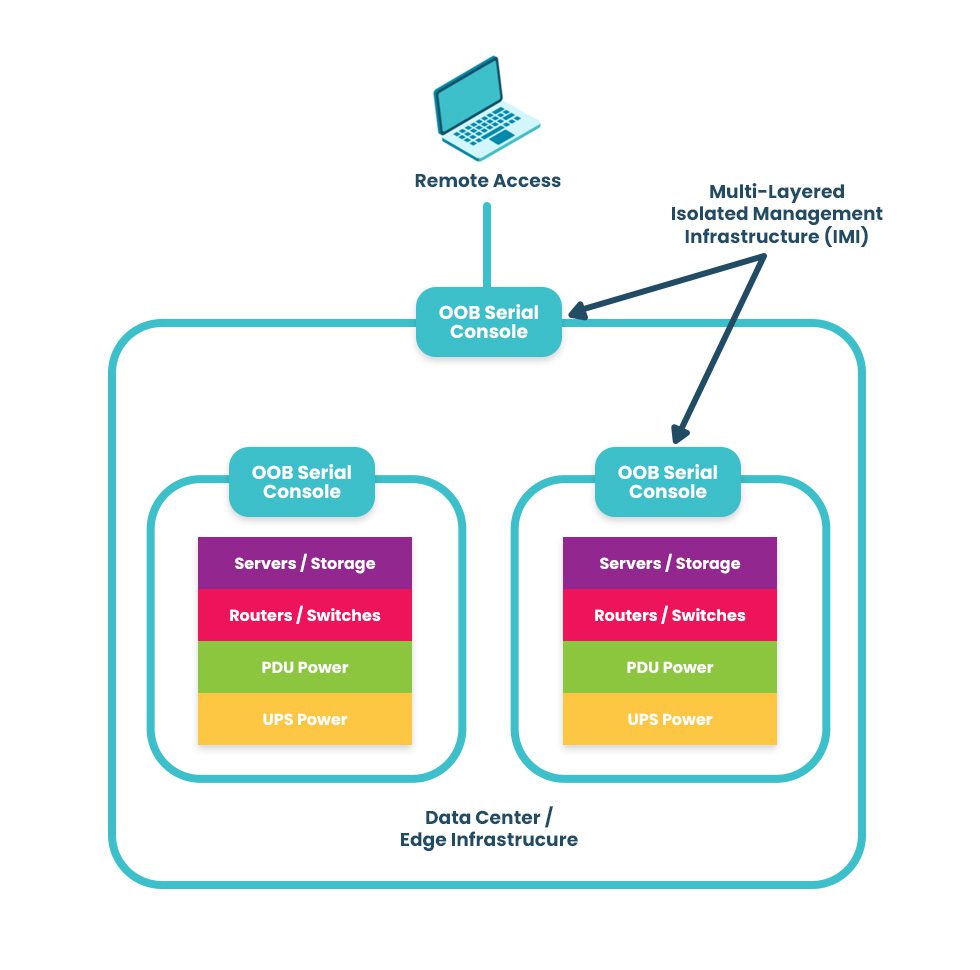 An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between
An IMI using out-of-band serial consoles also provides a safe environment to recover from ransomware attacks. The pervasive nature of ransomware and its tendency to re-infect cleaned systems mean it can take companies between
")

")