Overcoming the Challenges of PDU Management in Modern IT Environments

Power Distribution Units (PDUs) are the unsung heroes of reliable IT operations. They provide the one thing that nobody pays attention to unless it’s gone: stable, uninterrupted power. Despite their essential role in hyperscale data centers, colocations, and remote edge sites, PDU management often remains one of the least optimized and most overlooked areas in IT operations. As organizations grow and expand their infrastructure footprints, the challenges associated with PDU management multiply to create inefficiencies, drive up costs, and expose critical systems to unnecessary downtime.
Why PDU Management is a Growing Concern
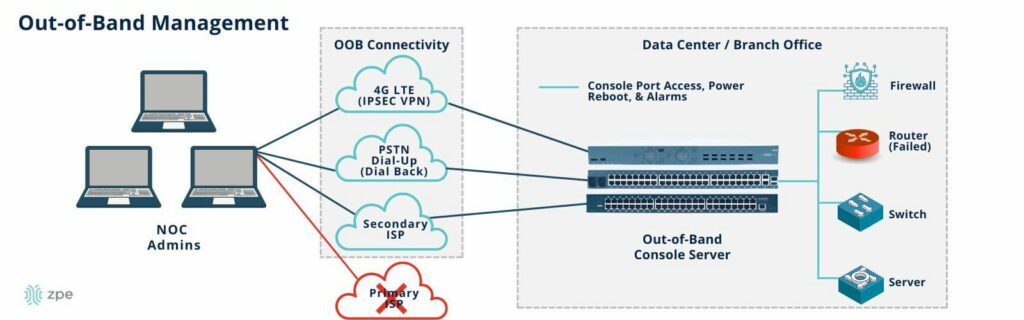
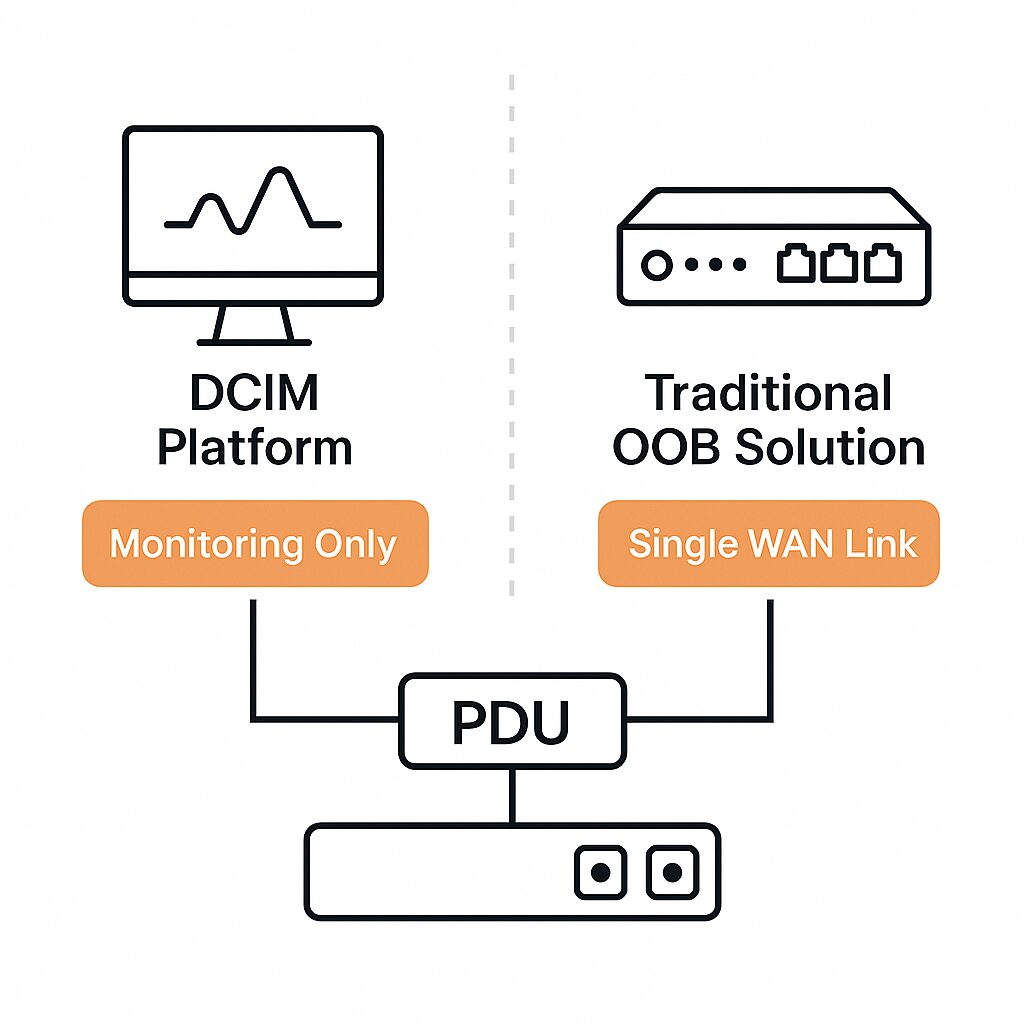
For enterprises that have adopted traditional Data Center Infrastructure Management (DCIM) platforms or out-of-band (OOB) solutions, it might seem like power infrastructure is already covered. However, these tools fall short when it comes to giving teams granular control of PDUs. Many only support SNMP-based monitoring, which means teams can see status data but can’t push configurations, perform power cycling, or recover unresponsive devices. OOB solutions also rely on a single WAN link, which can fail and cut off admin access.
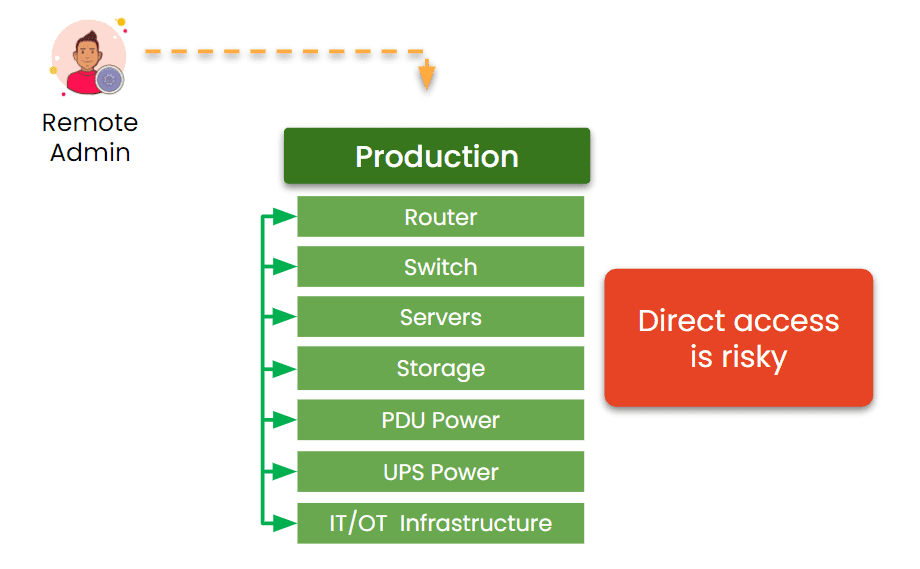
This lack of control results in IT teams still having to perform routine power management tasks on-site, even in supposedly modernized environments.
The Three Major Challenges of PDU Management
1. Operational Inefficiencies
Most PDUs still require manual interaction for updates, configuration changes, or outlet-level power cycling. If a PDU becomes unresponsive, or if firmware updates fail mid-process, SNMP interfaces become useless and recovery options are limited. In these cases, IT personnel must physically travel to the site – sometimes covering long distances – just to perform a simple reboot or plug in a crash cart. This not only introduces unnecessary downtime but also drains IT resources and slows incident resolution.
2. Slow Scaling
As businesses grow, so does the number of PDUs deployed across their infrastructure. Yet when it comes to providing network capabilities, power systems are not designed with scalability in mind. Even network-connected PDUs lack support for modern automation frameworks like Ansible, Terraform, or Python. Without REST APIs, scripting interfaces, or integration with infrastructure-as-code platforms, IT teams are left managing each unit individually through outdated web GUIs or vendor-specific software. This manual approach doesn’t scale and leads to costly delays, especially during site rollouts or large-scale upgrades.
3. High Administrative Overhead
Enterprises managing hundreds or thousands of PDUs across distributed environments face overwhelming complexity. Without centralized visibility, tracking the health, configuration status, or firmware version of each device becomes impossible. When each PDU requires its own login, manual updates, and independent troubleshooting processes, power management becomes reactive, not strategic. This overhead not only wastes time but also increases the risk of misconfigurations, security gaps, and service disruptions.
Best Practices for Modern PDU Management
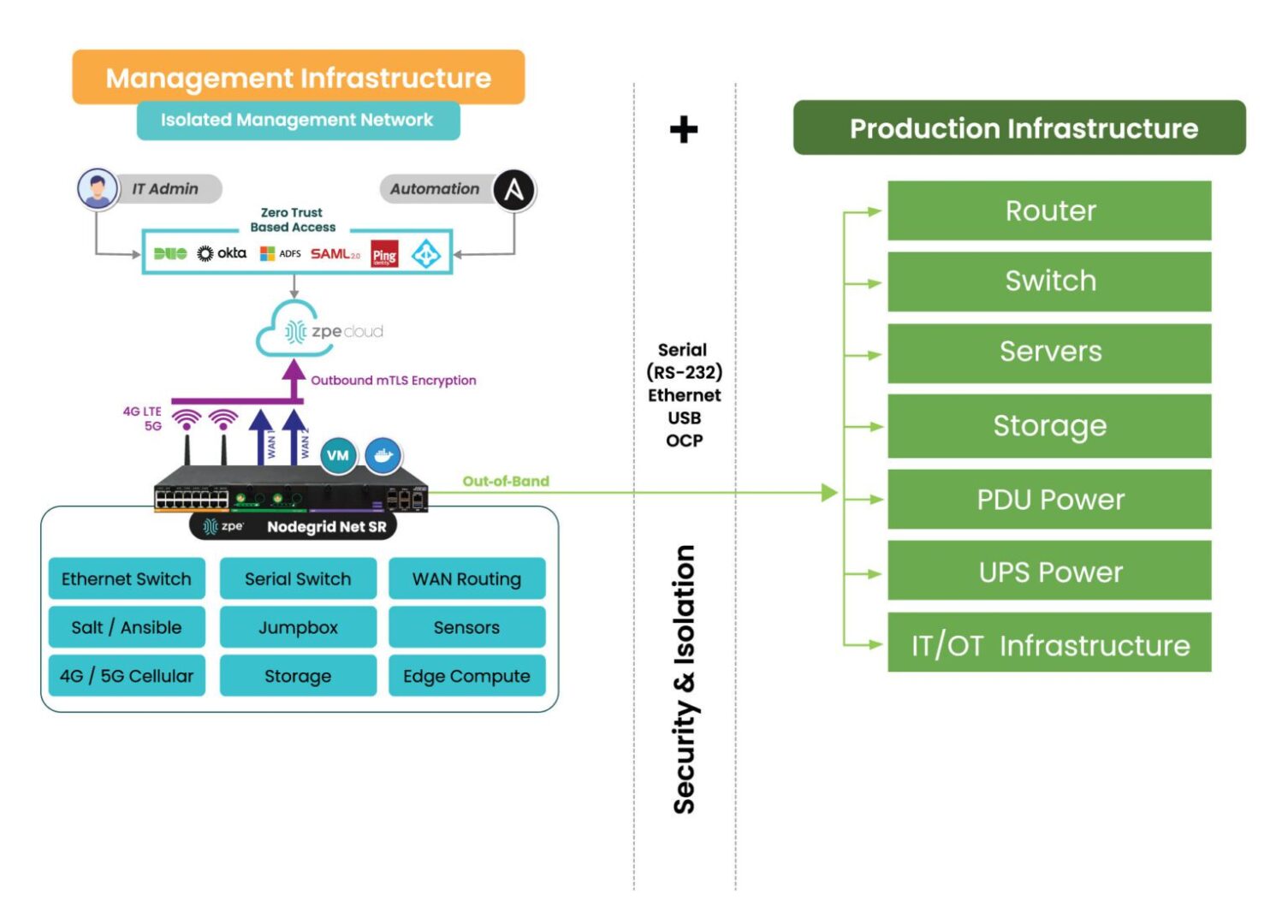
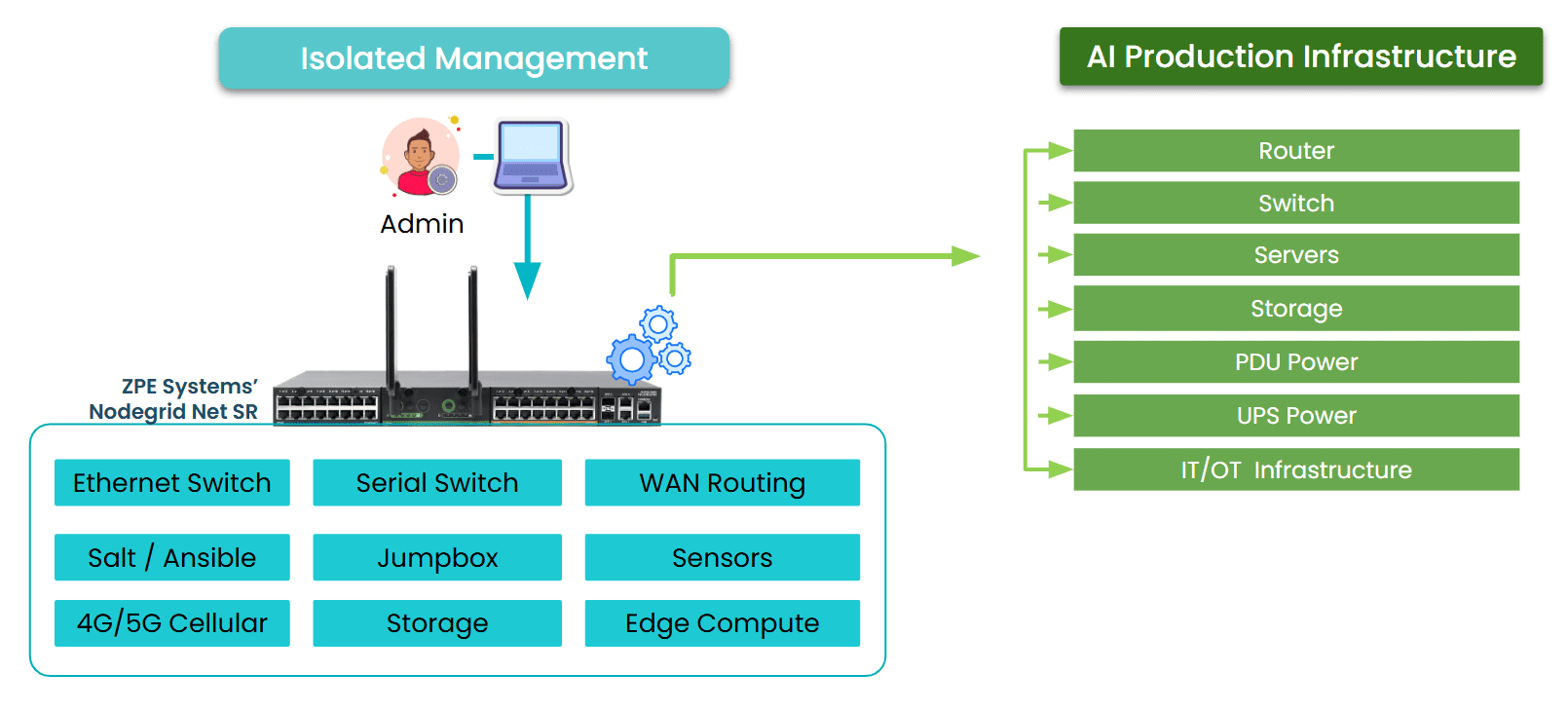
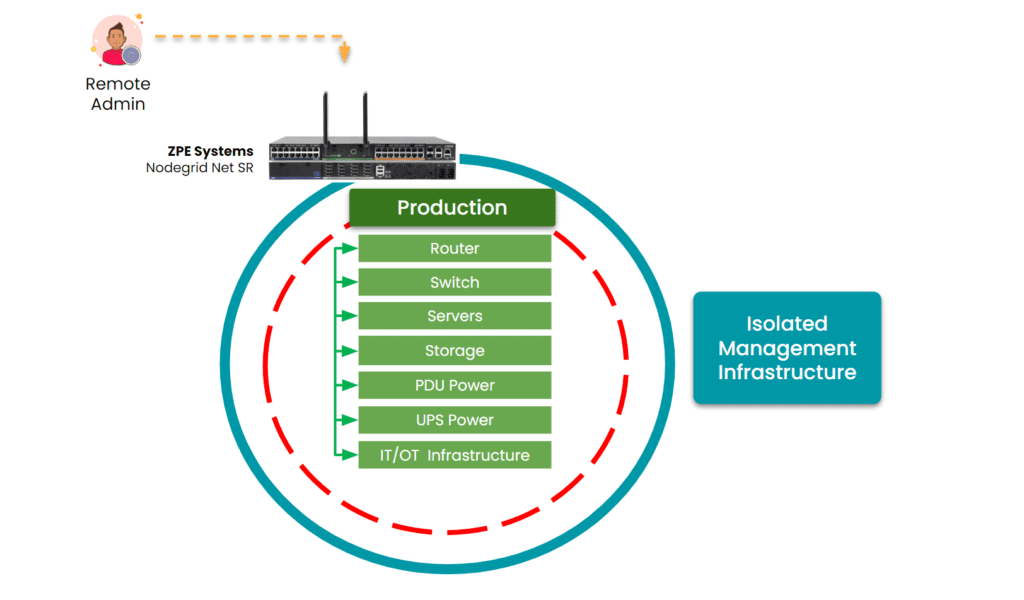
To move beyond these limitations, organizations must rethink their approach. The goal is to eliminate on-site dependencies, enable remote control, and consolidate management across all PDUs. This is where Isolated Management Infrastructure (IMI) comes into play.
1. Enable Remote Power Management
Connect PDUs to a dedicated management network, ideally through both Ethernet and serial interfaces. This allows for complete remote access, from initial provisioning to ongoing troubleshooting, even if the primary network link goes down.
2. Automate Everything
Adopt solutions that support infrastructure-as-code, automation scripts, and third-party integrations. By automating tasks like firmware updates, power cycling, and configuration pushes, organizations can drastically reduce manual workloads and improve accuracy.
3. Centralize Administration
Deploy a unified platform that can manage all PDUs, regardless of vendor or model, from a single interface. Centralization enables consistent policies, rapid issue resolution, and streamlined operations across all environments.
Learn from the Experts: Download the Best Practices Guide
ZPE Systems has worked with some of the world’s largest data center operators and remote IT teams to refine their power management strategies. IMI is their foundation for resilient, scalable, and efficient infrastructure operations. Our latest whitepaper, Best Practices for Managing Power Distribution Units in Data Centers & Remote Locations, dives deep into proven strategies for remote management, automation, and centralized control.
What you’ll learn:
- How to eliminate manual, on-site work with remote power management
- How to scale PDU operations using automation and zero-touch provisioning
- How to simplify administration across thousands of PDUs using an open-architecture platform
Download the guide now to take the next step toward smarter, more sustainable IT operations.

Get in Touch for a Demo of Remote PDU Management
Our engineers are ready to show you how to manage your global PDU fleet and give you a demo of these best practices. Click below to set up a demo.
More PDU Management Resources: